
I'm a Senior MLOps Engineer with 6+ years of experience building production-ML systems.
I write long-form articles on MLOps to help you build too!
Top-performing platforms, such as Netflix, Amazon, and YouTube, all leverage AI to analyze customer preferences and offer personalized content. They succeed not only by creating efficient ML models but, most importantly, by scaling their models to handle an unimaginable number of simultaneous users.
Scaling machine learning models in production is the strategy of making your application handle changes in traffic spikes by adjusting the number of model instances. This ensures that your system can manage more requests when needed.
Building a system to scale your ML models from scratch might not be optimal. Why re-creating the wheel when you can use a Model Serving Platform like Vertex AI or KServe? 🛠️🛞
By reading this guide, you will understand:
- What a Model Serving Platform is.
- How it integrates into the MLOps lifecycle.
- The reasons to use one.
- When it might not be necessary.
- The steps to scale machine learning models in production.
Model Serving Preliminaries
To scale machine learning models effectively, it’s important to know the key concepts of the model-serving field. If you are familiar with model servers, serving runtimes, and serving platforms, feel free to skip to the next section.
ML Development Lifecycle
First, let’s look at the ML development lifecycle to see where serving platforms come into play. Developing a production-grade ML application usually involves these key steps:
- Training: Using a machine learning framework, such as PyTorch or TensorFlow, we train a model on a specific task.
- Packaging: We package the trained model into a Docker image (also called Model Server).
- Deployment: Then, we deploy our Docker image into a production environment, either in the cloud or on-premise.
- Integration: At this stage, we link the deployed model to the application and its components (databases or features store) to process input data and return predictions.
- Monitoring: We regularly track the accuracy, latency, and hardware usage of our model to see how it performs in the production environment.
- Iterate: Based on the monitored metrics, we make data-driven decisions to change our AI application and return to step 1.
A Model Serving Platform steps in during the deployment and integration phases. It offers deployment features and helps scale ML models efficiently.
Key Components of Model Serving
To have a deeper understanding of how to scale machine learning models, let’s review the key components and concepts of the model serving field.
The Model Server
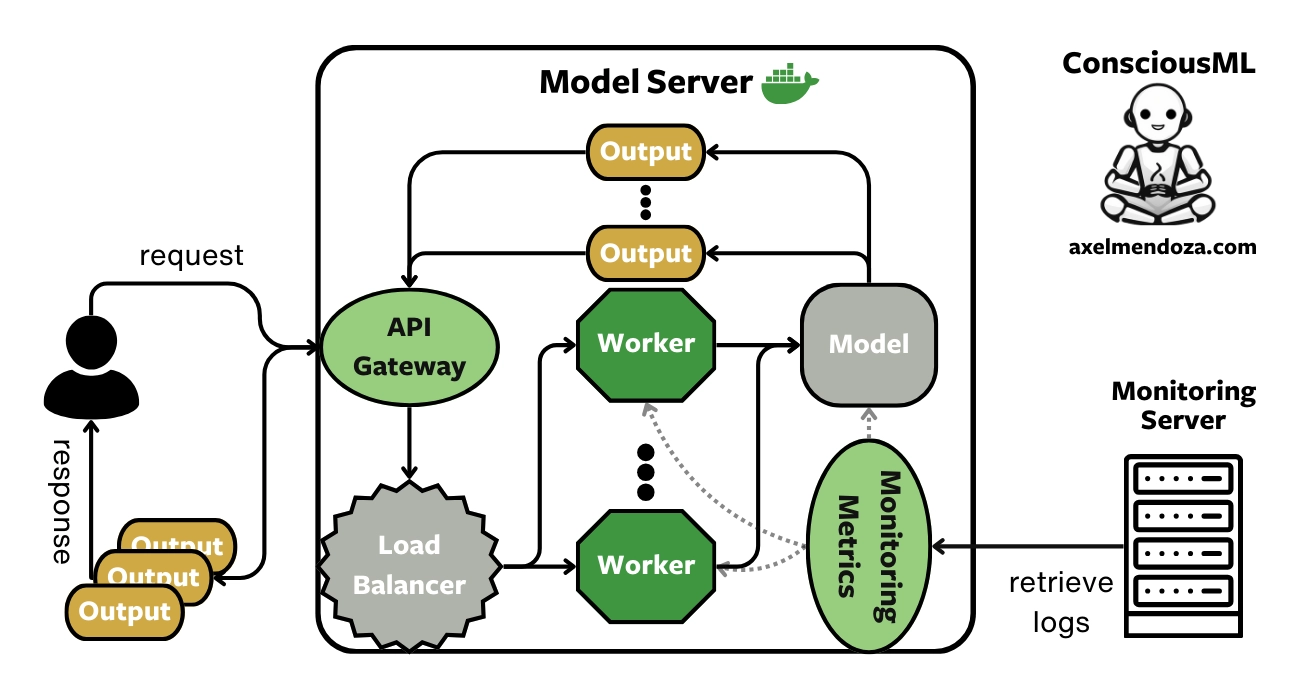
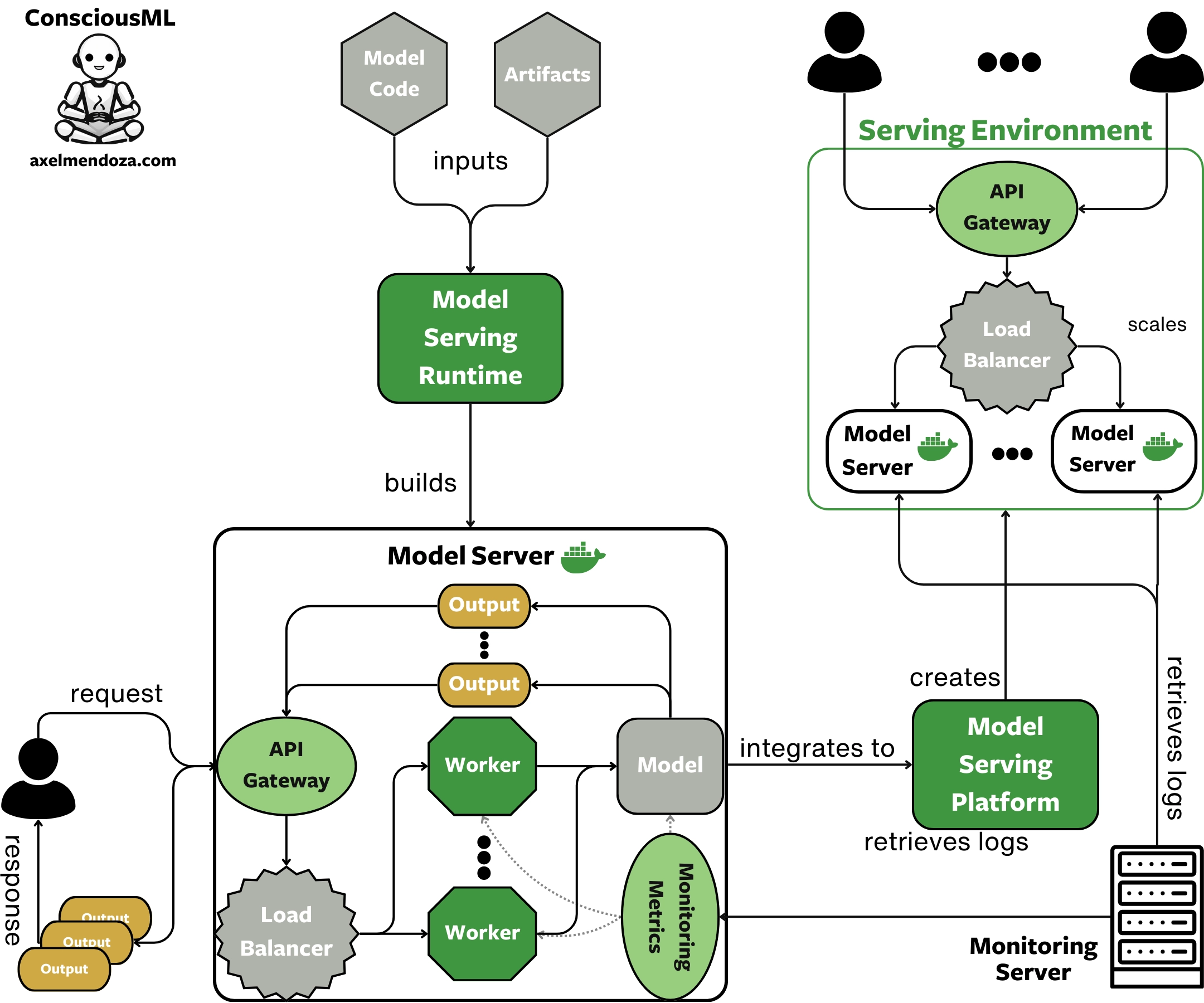
A Model Server is a Docker image that includes one or more machine learning models. It provides APIs to receive data, compute model predictions, and return them to the user.
We build a model server during the packaging process. It enables to make the transition between an experimental model and a production model.
Read our model server overview to learn everything you need to know about this key component of MLOps.
The Model Serving Runtime
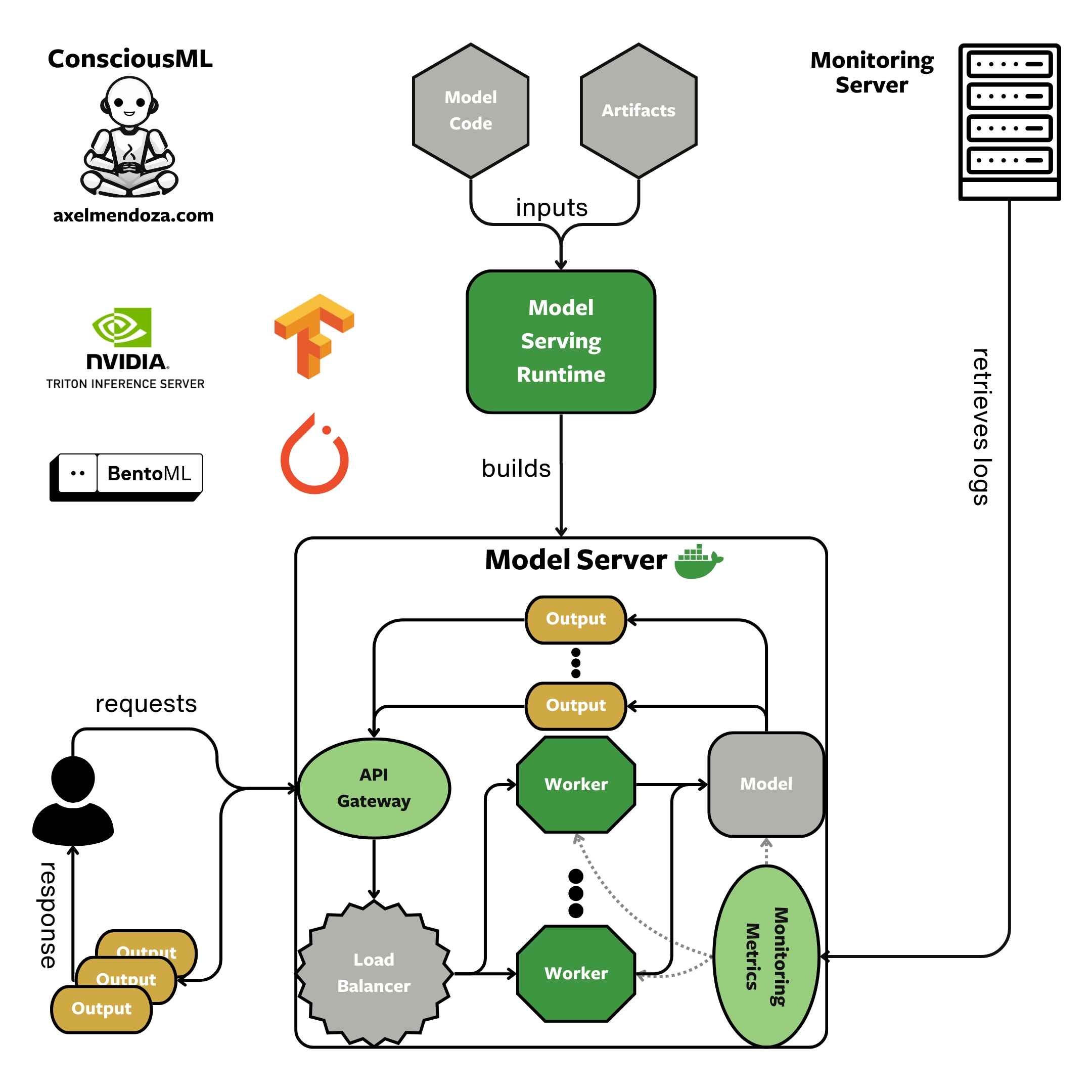
A Model Serving Runtime is a tool designed to build ML-optimized model servers. As you can see in the diagram above, by integrating the model code and artifacts in a serving runtime, we produce a model server with a complex architecture that efficiently supports ML workflows.
Tools such as TorchServe and BentoML are serving runtimes. Read our model-serving runtime overview to get the most out of these amazing tools.
Horizontal vs Vertical Scaling?
Horizontal and vertical scaling are not limited to the ML ecosystem. They are DevOps practices that were mature long before the advent of AI:
- Horizontal scaling: The process of increasing the capacity of a system by adding more machines or nodes to a distributed computing environment.
- Vertical scaling: Upgrading the resources (CPU, GPU, RAM, or storage) of an existing machine.
In the context of scaling machine learning models, we refer to horizontal scaling where each machine in the system runs one or more models. More specifically, auto-scaling is what we are aiming for.
What is Auto-Scaling?
Auto-scaling automatically adjusts the number of computational resources in an infrastructure environment.
This practice can be performed both on vertical and horizontal scaling. However, auto-scaling usually refers to automatic horizontal scaling.
In simpler terms, it adjusts the number of machines according to traffic. For ML models, this means automatically changing the number of model server instances as needed.
Before diving into the main topic of this guide, we have one last concept to understand.
What is Scaling-to-zero?
For ML applications, scaling-to-zero is the ability to reduce the number of machines running ML models to zero.
This strategy ensures that there are no idle machines in our production environment when not needed. In some contexts, this feature can be very important, as the hardware (GPU) needed to run large ML models is very costly. Shutting down machines when not needed can save a considerable amount of cloud costs for applications with downtimes.
Now that we have the necessary model serving preliminaries, let’s discuss the core concept of this article! 👀
What is a Model Serving Platform?
In real-time scenarios, one model server instance is usually not enough to handle multiple simultaneous requests. For high-volume batch pipelines, multiple model instances may be needed to compute the predictions in time.
That’s when the Model Serving Platform steps in! It is a system that builds an environment to deploy and scale model server instances automatically according to incoming traffic.
These platforms, such as Amazon SageMaker or BentoCloud, offer utilities to build and manage the underlying infrastructure necessary for auto-scaling.
The Serving Platform Architecture for Auto-Scaling
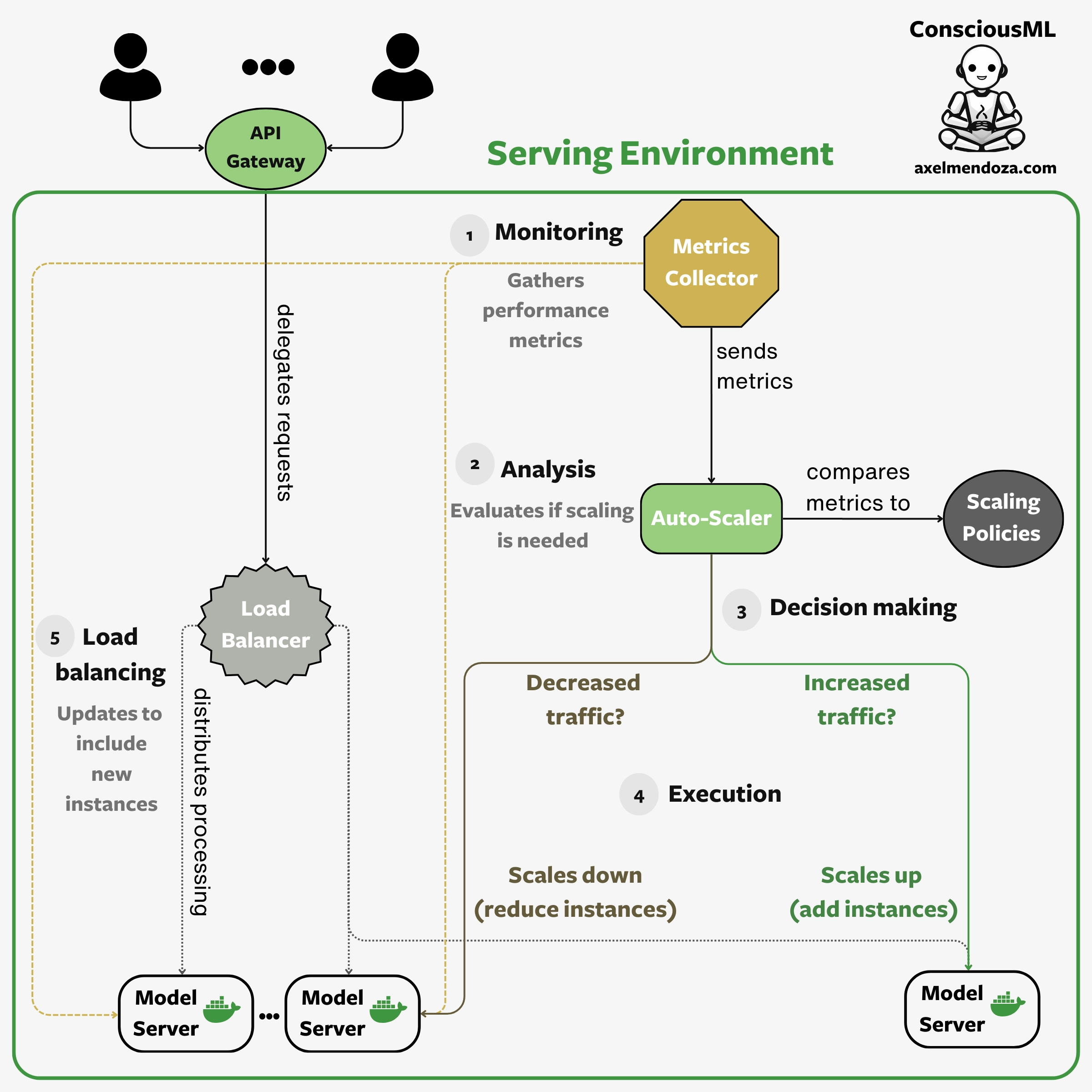
Now that we know how serving platforms work, digging deeper and understanding their sophisticated architecture wouldn’t hurt!
Auto-Scaling Components
Serving platforms support auto-scaling: they dynamically adjust computational resources allocated to ML models based on real-time demand. Here’s an overview of the main components involved in this process:
- Load balancer: Distributes incoming requests evenly across multiple model instances to prevent any single instance from being overloaded, ensuring high availability and performance.
- Metric collector: Monitors hardware performance metrics of the model servers, such as CPU or GPU usage, memory usage, request rate, and latency. These metrics provide insights into the current load and resource utilization.
- Auto-scaler: Analyzes the collected metrics and makes scaling decisions based on predefined policies. It determines whether to scale out (add more instances) or scale in (remove instances).
- Model server: A machine running an ML model and exposing APIs to receive data and return predictions.
- Scaling policies: Predefined rules that guide the decisions of the Auto-scaler. These can be based on thresholds (CPU usage > 70%), schedules (scale-up during business hours), or predictive models to anticipate future demands.
Auto-Scaling Workflow
Let’s now explore the step-by-step workflow that enables auto-scaling in serving platforms:
- Monitoring: The metrics collector gathers performance data from the model instances continuously.
- Analysis: The auto-scaler analyzes these metrics against the scaling policies to determine if scaling actions are needed.
- Decision making: If metrics show increased demand (such as high CPU usage or request rate), the Auto-scaler adds more model instances. If demand goes down, the Auto-scaler reduces the number of instances.
- Execution: The Auto-scaler triggers the scaling actions, adding or removing model instances as needed.
- Load balancing: The Load balancer updates its configuration to include the new instances in the pool of available resources and evenly distribute the incoming requests.
Reasons You Need a Model Serving Platform
Suppose you do not use a serving platform. Instead, you choose to deploy your model on a virtual machine (VM) on-premise or in the cloud. This setup has the clear advantage of being easy to implement. However, serving platforms have many benefits compared to a simple VM configuration:
- Handling high-traffic: In high-traffic situations, where many requests must be processed quickly, one model instance may not be enough. A serving platform lets you adjust the number of instances up or down based on the incoming requests.
- Reduce cloud costs: Serving platforms control the number of active containers, optimizing resource use and reducing cloud costs. For example, you can use a scaling-to-zero approach to ensure there are no idle machines when not needed.
- Deployment strategies: These platforms support advanced deployment strategies, such as Canary or A/B testing, to make the deployment process safer and more reliable.
- Built-in model monitoring: Platforms like Vertex AI or SageMaker support model monitoring out-of-the-box, providing a dashboard to track how your models perform in production
When is a Model Serving Platform not Necessary?
- Low Traffic: When your application does not experience many requests at once, a single model instance might be enough.
- Lightweight models: For models that just require minimal resources and have fast inference, the additional features of a model serving platform might not justify the extra complexity.
- Batch pipelines: When batch processing is used and there is no tight deadline to get the responses, the scaling features of a model serving platform might not be needed.
Serving Runtime vs Serving Platform
A serving runtime helps us build ML-optimized model servers while a serving platform manages the infrastructure to deploy and scale model instances.
You might wonder, should I choose one or the other? You can use both! In fact, depending on the platform’s specifications, you can integrate the model server you built with a serving runtime into a serving platform.
It’s worth noting that some platforms provide pre-built containers that, under the hood, use a serving runtime. For example, Vertex AI supports Nvidia Trithon images.
At the cost of extra engineering, using both tools will yield the benefits of one and the other.
Serving Platform vs MLOps Platform
Following our definition, the main difference between a serving platform and an MLOps platform is that the MLOps platform supports more features to cover the whole machine learning life cycle, such as workflow orchestration, experiment tracking, data versioning, and more.
In contrast, a serving platform primarily focuses on deploying and serving models. However, some platforms included on our list are also MLOps platforms like SageMaker and Vertex AI. It simply means that you can use them as a serving platform, but their features are not limited to it.
Steps to Scale Models in Production
Now that you have all the knowledge required to fully grasp the model serving ecosystem, we will see practical steps to scale your model.
1. Use a High-Performance Runtime
High-performance runtimes like TensorRT or ONNX Runtime are faster than ML frameworks like PyTorch or TensorFlow. They can significantly reduce model inference time. In some scenarios, it can speed up your model inference time by 30 times or more!
The conversion process can be complex, but it is worth the effort! If you use compute-intensive models, choose a model serving runtime that supports your ML-optimized runtime.
2. Choose the Appropriate Hardware
The hardware you choose significantly impacts the inference time of your models. For computationally intensive models, consider using one or multiple graphics cards (GPU) to speed up the processing.
Unfortunately, GPUs are costly, so they shouldn’t be a go-to solution. If your model is less demanding, a CPU might be enough. Assess the resource needs of your model and select hardware that balances cost and performance.
3. Build a Model Server
Use a model-serving runtime like TensorFlow Serving or NVIDIA Triton to package your trained ML model into a Docker image with APIs to receive input data and serve the predictions.
These tools ensure that your model server is optimized for model inference, making it easier to deploy across different environments.
Unsure about which serving runtime to use? Read our guide to the best model serving runtimes to find the tool that suits your needs.
4. Use a Model Serving Platform
Deploy your model server on a model-serving platform like Seldon or KServe. These platforms automatically manage the underlying infrastructure and scale the number of model instances based on traffic.
They offer features like auto-scaling, scale-to-zero, integration with other MLOps tools, advanced deployment strategies, and built-in model monitoring.
5. Monitor Performance
To iteratively improve your applications, regularly monitor your model’s performance in production. Track these key metrics to improve your application iteratively:
- Inference metrics: Monitor latency, throughput, and resource usage to identify any bottlenecks.
- Machine learning metrics: Use accuracy, mean average precision, or any other production metric to assess the performance of your model according to your application’s Key Performance Indicators (KPIs).
- Data metrics: Regularly inspect data drift, concept drift, or input data quality.
Make data-driven decisions based on these metrics to adjust your model, runtime, or infrastructure to maintain optimal performance. Many serving platforms, such as Vertex AI or SageMaker, provide built-in monitoring tools to help you easily keep track of these metrics.
Conclusion
Scaling machine learning models in production is crucial for real-time ML applications and large batch pipelines, as it helps you meet the KPIs of your machine learning products
Leveraging Model Serving Runtimes eases the serving and deployment process by providing utilities to package your ML models into efficient Docker images with APIs to receive requests, perform the inference, and return predictions.
Using Model Serving Platforms is key as they support auto-scaling, which optimizes hardware usage by automatically adjusting resources based on demand.
Remember these steps to design a best-in-class scaling application:
- Use a high-performance runtime: Choose runtimes like TensorRT or ONNX Runtime to reduce the inference time of your models significantly.
- Select the right hardware: Use GPUs for intensive models or CPUs for less demanding models.
- Build a model server: Use a serving runtime to package your trained model and build a model server with ML APIs.
- Deploy on a serving platform: Integrate your model server in a serving platform to enable auto-scaling and advanced deployment strategies.
- Monitor performance: Track inference, machine learning, and data metrics to maintain optimal model performance.
Scaling ML products is a challenging journey. Consider paid, fully managed options to speed up development and reach your goals faster. Good luck with your MLOps adventures!