
I'm a Senior MLOps Engineer with 6+ years of experience building production-ML systems.
I write long-form articles on MLOps to help you build too!
Are you struggling to choose the best tool to build efficient machine learning APIs? You are not alone!
AI applications have become increasingly demanding. Data volumes and model inference times are skyrocketing, and simple solutions like Flask+Docker fail to support real-time machine learning and high-volume data pipelines.
Model Serving Runtimes are tools that tackle this issue. This guide will help you build ML-optimized Docker images with APIs for your application by providing an in-depth comparison of the best available options.
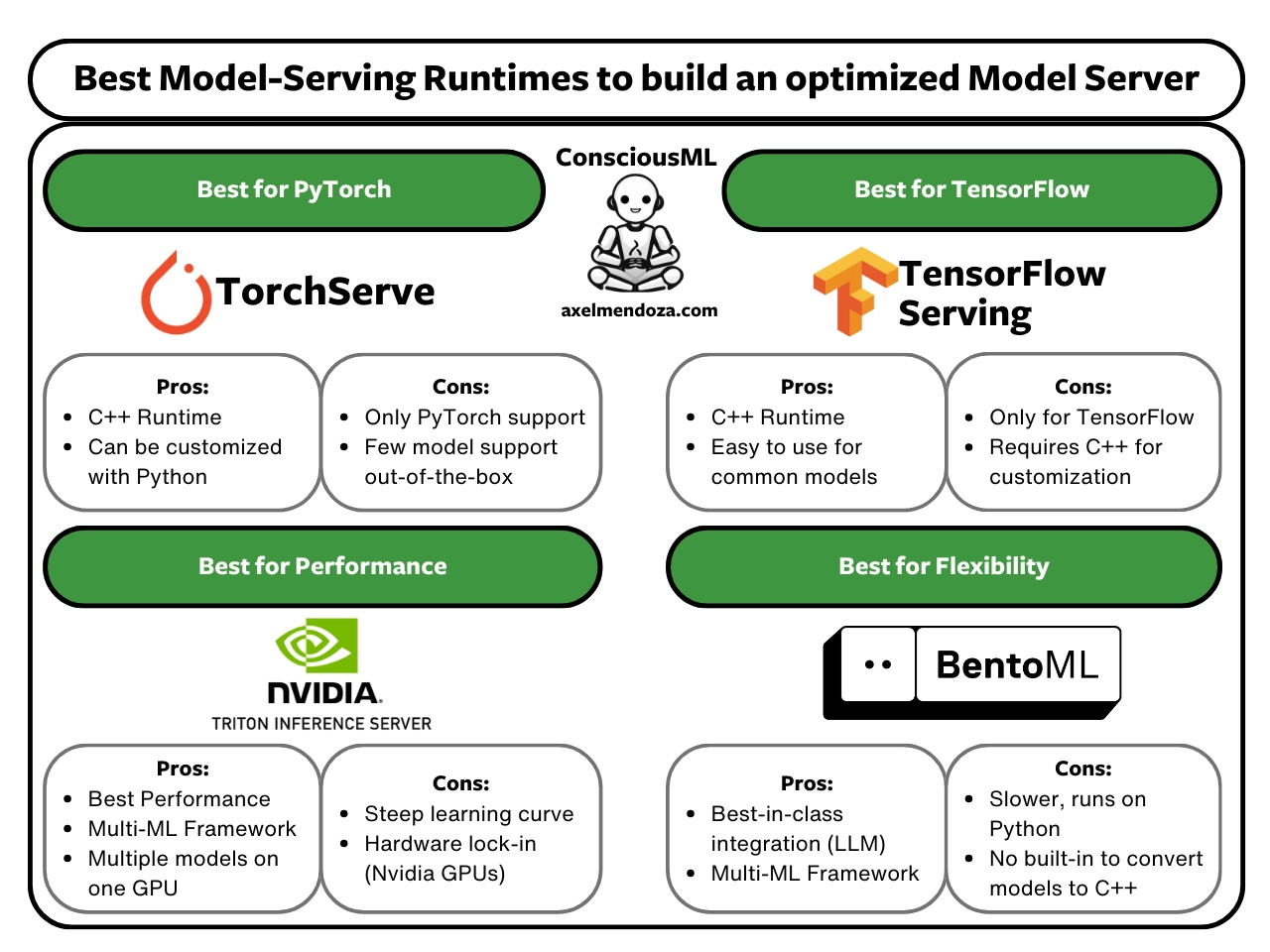
We will thoroughly compare the main features, pros, and cons of TensorFlow Serving, TorchServe, BentoML, and Triton Inference Server to help you find the tool that best fits your team and needs.
By the end of this article, you will fully understand:
- What is a Model Server?
- Model Serving Runtimes and their interaction with Model Servers.
- How to choose the best serving runtime for your needs?
- All the leading tools to build efficient APIs.
Let’s start by understanding the preliminaries: the Model Server.
What is a Model Server?
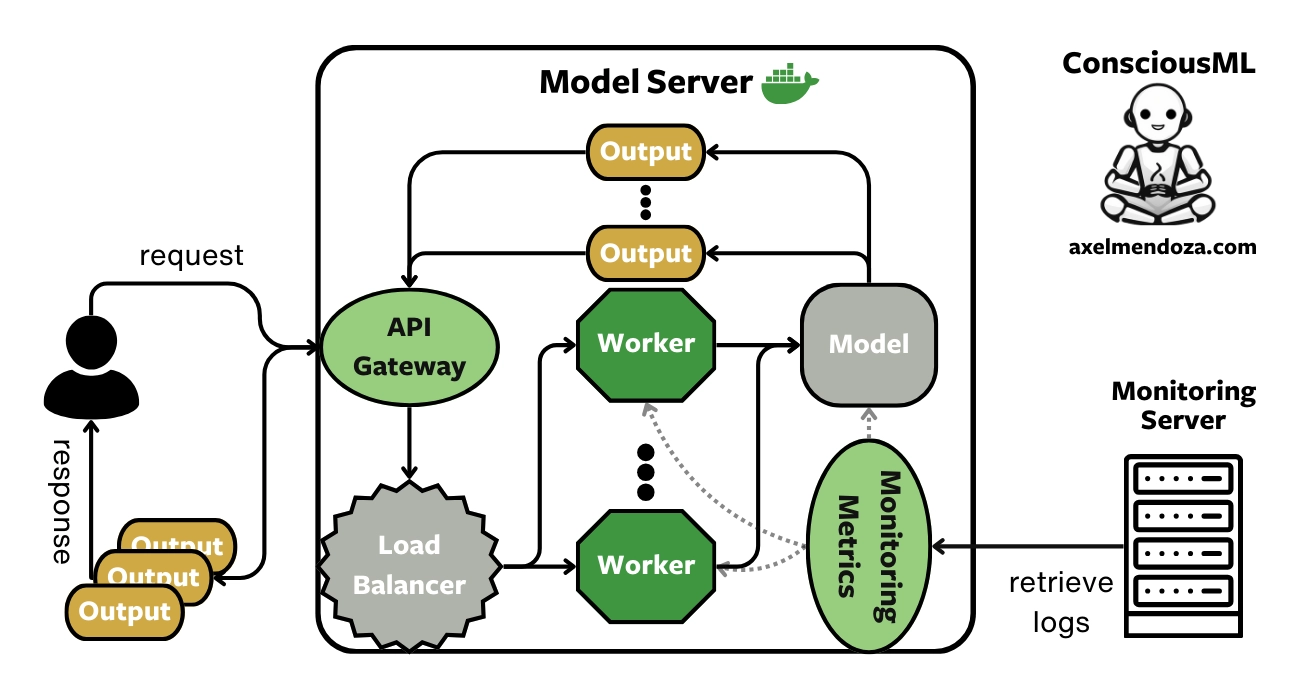
A Model Server is a Docker image containing one or more machine learning models, exposing APIs to handle incoming requests (data), perform inference, and serve the model predictions.
This MLOps component is crucial to understand to get a full grasp of the model serving big picture. Read more in our model server overview.
What is a Model Serving Runtime?
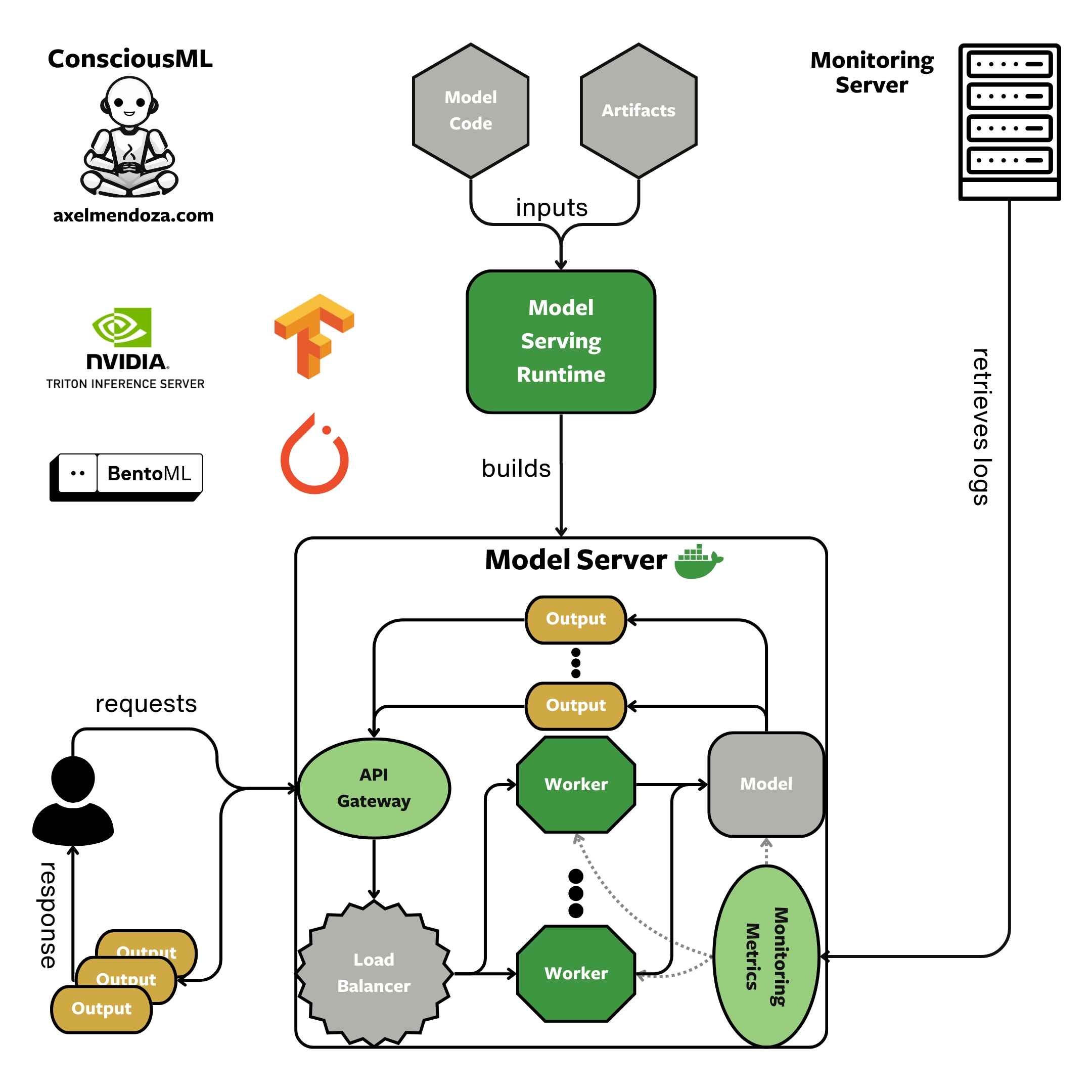
A Model Serving Runtime is a tool that aims at creating ML-optimized Model Servers. Simply put, it packages trained machine learning models into a Docker image and creates APIs optimized for ML inference. This image can be used to create Docker containers, which are then deployed in production to receive REST or gRPC requests and provide predictions.
Read our model serving runtime overview to understand:
- The benefits of serving runtimes.
- When do you need one?
- The scenarios where they are not necessary.
- How to scale your ML models?
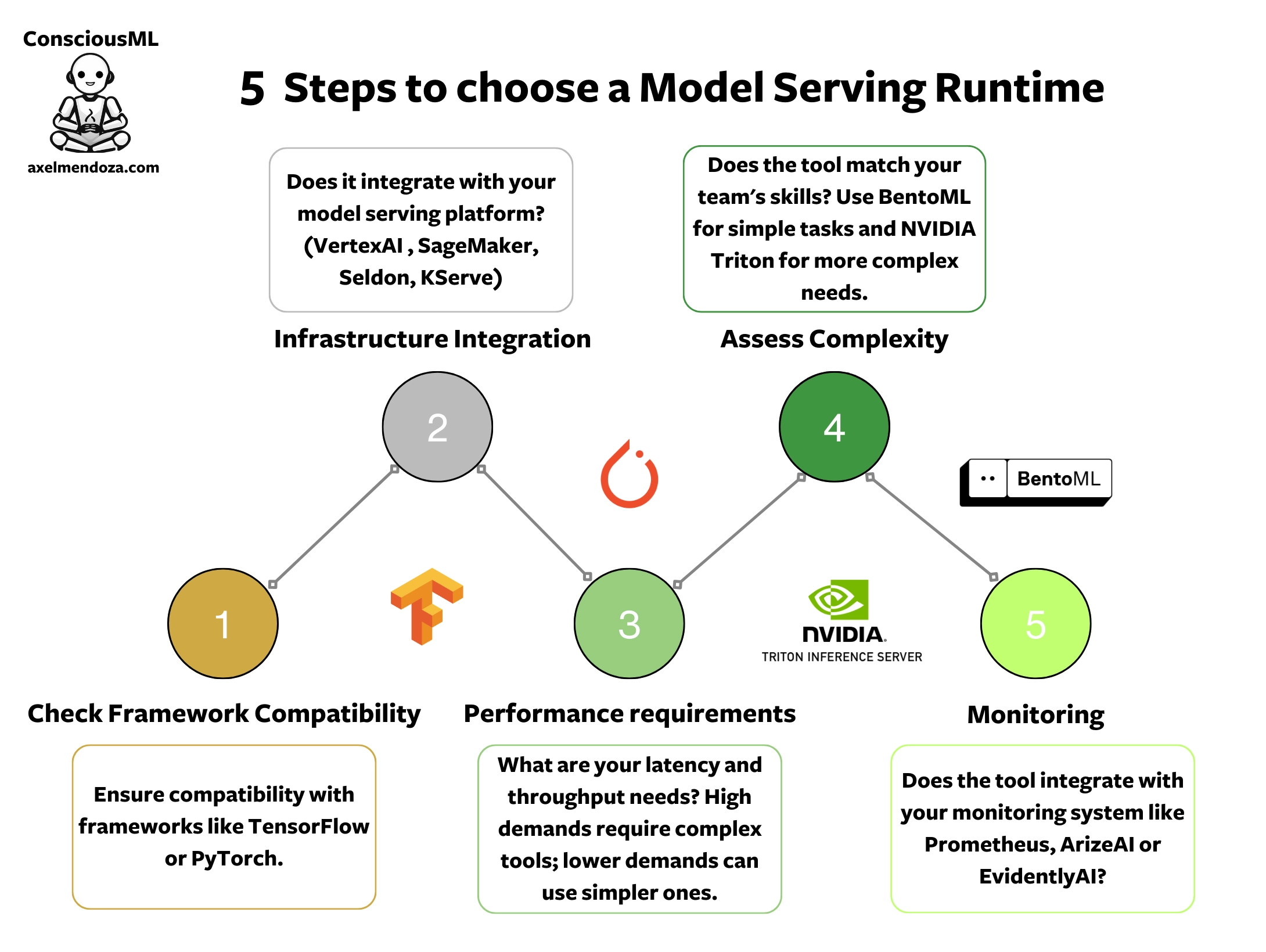
How to Choose a Model Serving Runtime?
Framework and Runtime Support
Serving runtimes are the tools that load, manage, and use your models. The first priority is to ensure they support the machine learning framework you use to train these models.
High-performance runtimes like TensorRT or ONNX Runtime can drastically speed up model inference time. If you plan to use compute-intensive models, you should select a model serving runtime that supports your ML-optimized runtime of choice.
Model Inference Performance
Model serving runtimes support multiple optimization features to reduce your model latency and increase throughput:
- Multi-hardware: Loads one model per GPU or CPU to parallelize the computing across multiple devices.
- Adaptative batching: The server can group simultaneous requests in a batch to process the data in one forward, improving efficiency and speed.
- Native high-performance runtime: Some serving runtimes support ML-optimized runtimes natively instead of running the models on a less efficient runtime like Python.
- gRPC inference protocol: The gRPC protocol is an alternative to the REST protocol. It is more efficient for intensive workloads such as AI applications.
- Asynchronous APIs: Enables the server to process multiple requests concurrently. The system becomes more responsive because it doesn’t need to wait to finish one request before starting another.
- Concurrent model execution: Loads many models or multiple copies of the same model on one GPU or CPU. You can run multiple models simultaneously using just one piece of hardware. This is huge as it increases performance by a multiple of the number of models per processing unit. However, if your model is too large to be loaded at least twice on the device, you will not benefit from this feature.
Stack Integration
Production-ready ML projects usually require multiple features, rarely supported by a single tool. For a model server to operate properly, the following integrations are worth considering:
- Model-serving platform: Platforms like Amazon SageMaker adjust the number of model servers based on the traffic they receive. These platforms handle variations in request volume over time while optimizing hardware resource utilization, thus reducing cloud costs.
- Monitoring tool: Serving runtimes serve Prometheus metrics on dedicated endpoints. Unfortunately, to monitor your models effectively, you will need an external tool to read, analyze, and display these metrics such as a Prometheus server or a fully managed tool like ArizeAI.
When choosing a serving runtime, it is crucial to pick one that can integrate with your existing MLOps stack. Additionally, you should plan which tools you might use in the future to select the optimal serving runtime for your ML projects and team.
Learning Curve
Model Serving Runtimes are complex systems. Developing with these tools is no easy feat. Their steep learning curve requires strong software skills and a good understanding of the framework’s concepts.
However, the implementation complexity varies greatly among serving runtimes. For example, the model configurations from NVIDIA Triton are far from trivial. Whereas BentoML is easier to use but supports fewer features.
4 Steps to Choose a Serving Runtime
- Identify the core features you need.
- Make a list of the tools that support these features.
- Choose the framework with the least complexity.
- Finally, assess the software skills of your team to ensure they match your framework of choice.
Now that you know everything you need to choose the right tool for your team and use case, let’s look at the advantages and disadvantages of each model serving runtime on our list.
Best Model Serving Runtimes
Before starting, it is worth noting that all the tools on this list support the following features:
- Free to use: Every tool on our list is licensed on Apache 2.0, so you can use it for commercial purposes for free.
- Multi-hardware: Spreads computing across several devices simultaneously.
- Adaptative batching: Groups requests for faster processing.
- gRPC protocol: Enables quick, low-latency communication between services, ideal for AI tasks.
- REST APIs: Simple and flexible system for client-server communication.
- Asynchronous APIs: Processes multiple requests at once for quicker response.
- Monitoring endpoint: Reports model performance, accuracy, and response times.
Tensorflow Serving
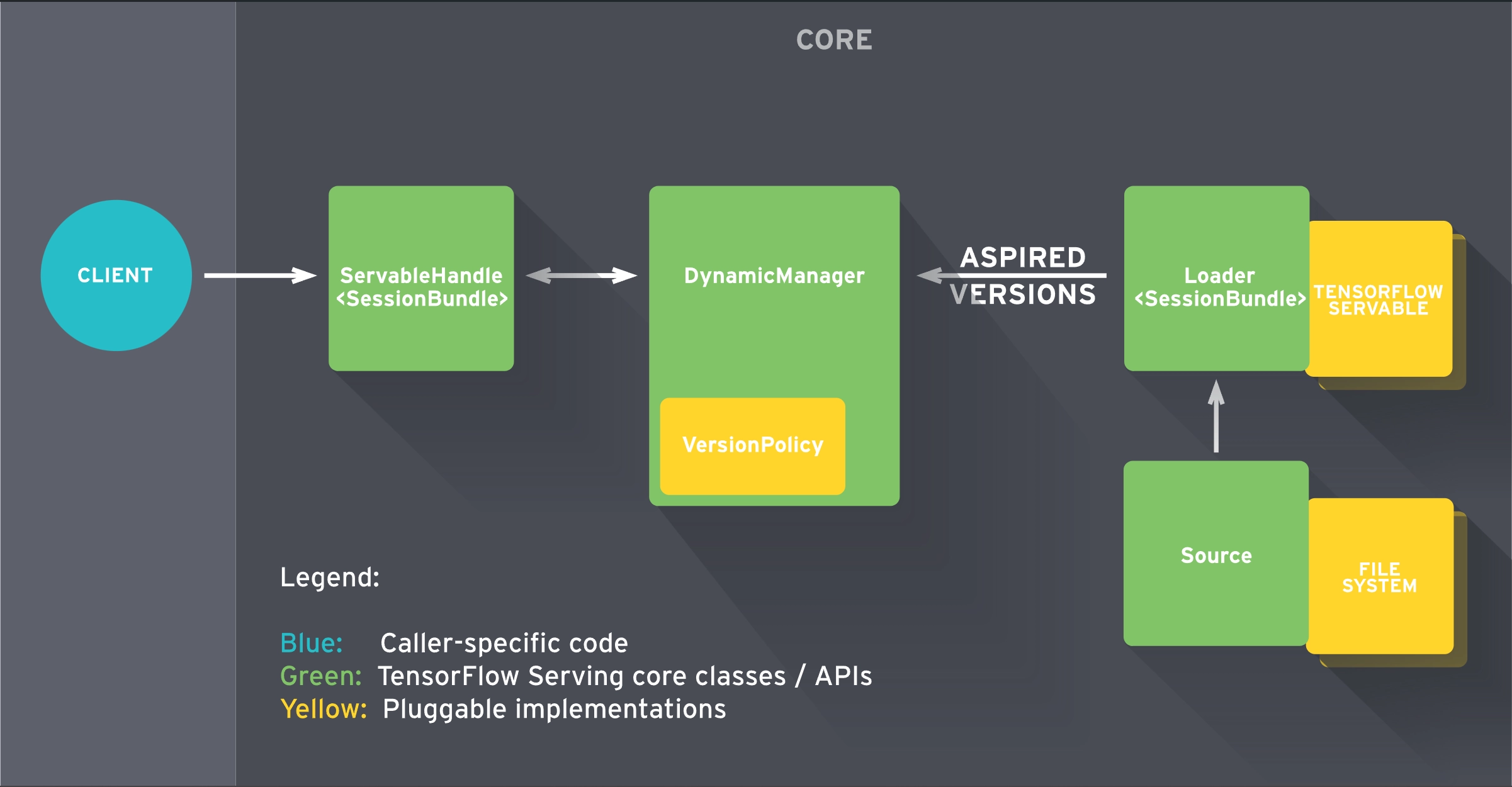
TensorFlow Serving (TFX) is a high-performance serving runtime designed to package TensorFlow models into ML-optimized containers.
Advantages of Tensorflow Serving
- Native high-performance runtime: After exporting your TensorFlow model from Python, TFX containers natively run on C++. This is a significant speed-up compared to serving runtimes that run on Python.
- Easy to use: To package TensorFlow models, you just need to run a single command in Docker and write a few lines of Python code.
- Customization: TFX lets you customize its core modules to implement some logic that is not supported.
Drawbacks of Tensorflow Serving
- ML framework restriction: TFX only supports TensorFlow and Keras models.
- No concurrent model execution: This framework does not support loading multiple replicas of a model on the same GPU.
- No LLM support: TFX does not offer official documentation for serving Large Language Models.
- Customization complexity: You will need some C++ skills to implement custom steps. That can be a major setback as many ML engineers, such as myself, mainly develop with Python.
- Documentation: The documentation lacks a clear direction. You don’t get a structured walkthrough of the core concepts.
Summary of TensorFlow Serving
If TensorFlow is your deep learning framework of choice, TFX is a really strong option. It runs on C++, and its inference performance is excellent.
However, packaging specific models that use custom operations in their graph can require considerable implementation effort.
TorchServe
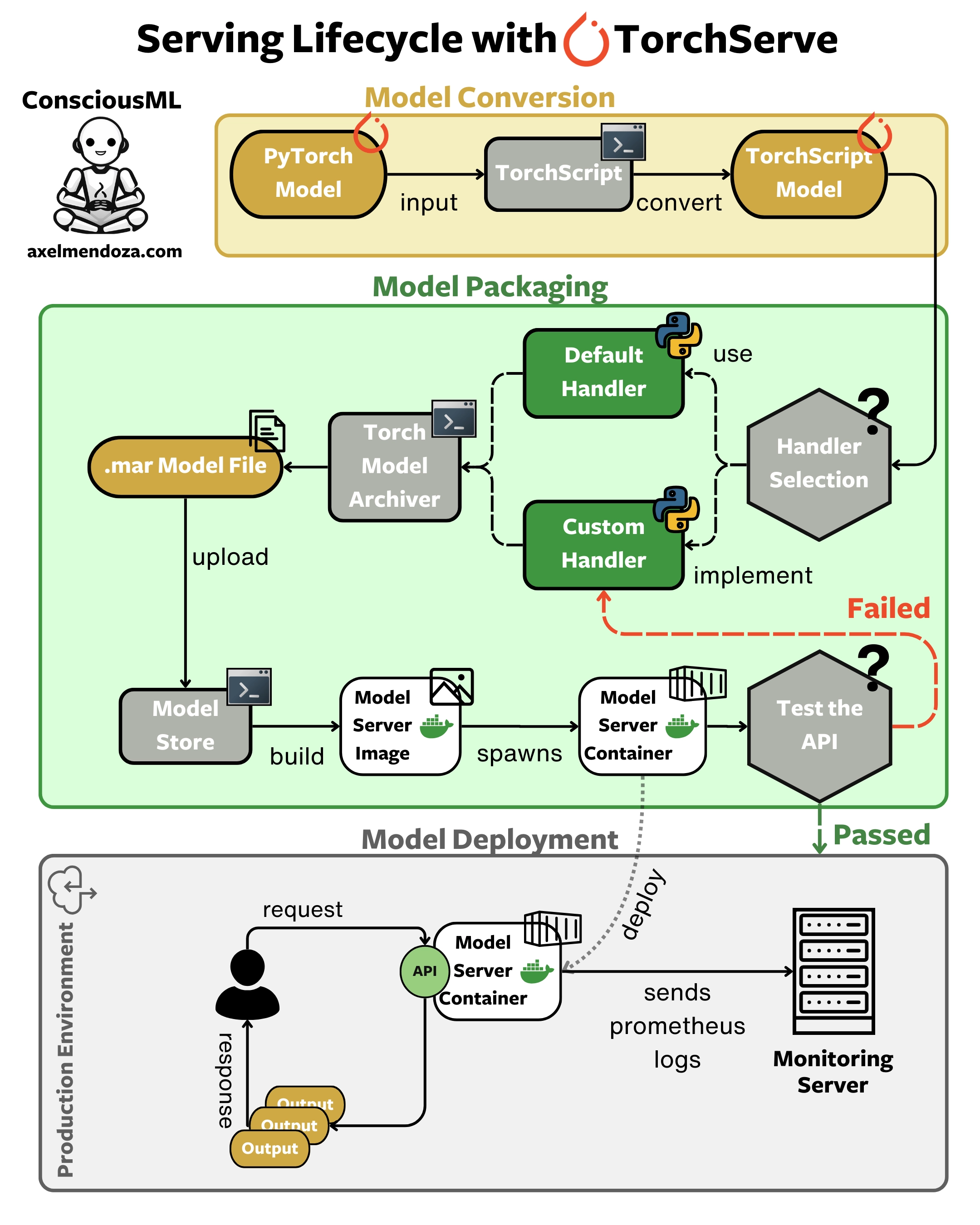
TorchServe is a high-performance serving runtime designed to build efficient Docker containers for your PyTorch models.
As shown in the flowchart above, here are the main steps to build and deploy a model server with TorchServe:
Convert your model: Transform your PyTorch model to TorchScript. This optimization step is crucial as it separates your model from the Python runtime, allowing it to run in C++. The result? A significantly faster model.
Handler selection: Choose a handler for your model. Handlers act as intermediaries, managing input preprocessing and output postprocessing. You can use a default handler or create a custom one tailored to your model’s needs.
Model packaging: Use the
torch-model-archivercommand-line tool to package your model, handler, and any necessary files into a Model Archive (.mar) file. This archive contains everything TorchServe needs to serve your model.Model store setup: Create a directory to serve as your model store. This is where TorchServe will look for models to serve. Place your .mar file in this directory.
Containerization: Build a Docker image containing your TorchServe setup. This step allows you to run your model server in any environment that supports Docker.
Server testing: Start the TorchServe server and test it using the inference API. This step ensures that your model server functions correctly before deployment.
Monitoring setup: Configure Prometheus to monitor your model’s performance metrics in production. This step is crucial for maintaining the health and efficiency of your deployed model.
Deployment: Deploy your Docker container to your production environment, whether cloud-based or on-premise. Your model is now ready to receive inputs and return predictions in your application.
Advantages of TorchServe
- Native high-performance runtime: Similarly to TFX, the model servers produced by TorchServe use the C++ runtime, resulting in best-in-class model inference performance.
- Easy to use: With TorchServe, you can easily package standard deep learning models with the Docker CLI. However, if the default handlers do not support your model workflow, you will need to extend the Python class to create your own.
- Customization: You can find straightforward instructions to customize the interactions between the TorchServe service and your ML models, such as model initialization, inference, pre-processing, and post-processing.
Drawbacks of TorchServe
- ML Framework restriction: TorchServe only supports PyTorch.
- No concurrent model execution: You can’t use TorchServe to run more than one instance of a model on a single GPU or CPU.
- Documentation: Although the TorchServe documentation covers more topics than TFX’s, it feels like an unorganized list of features.
- No LLM support: The documentation does not mention how to serve Large Language Models.
Summary of TorchServe
TorchServe is one of the best model-serving runtimes for teams that exclusively train their models with PyTorch.
The default inference handlers are restrictive as they only support image classification, segmentation, object detection, and text classifier.
However, the TorchServe community is active and offers many unofficial guides on how to build model servers for all kinds of models.
BentoML
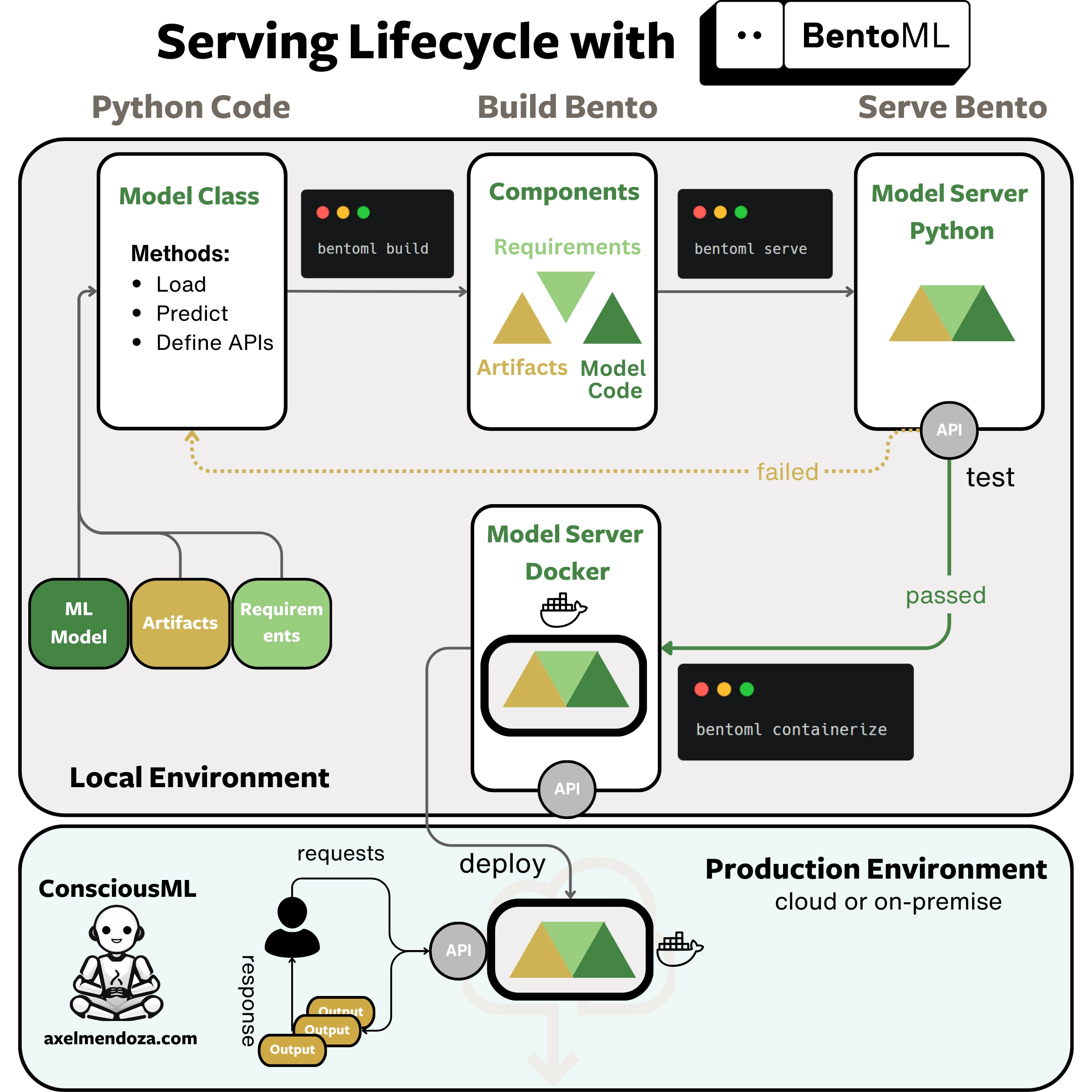
BentoML is a Python framework that thrives at building ML-optimized model servers for a wide variety of use cases, such as Large Language Models (LLMs), image generation, speech recognition and many more.
Bentos are the core concept of this framework. It is an archive containing everything needed to build a machine learning model server, such as source code, model architecture, data, and configurations.
As shown in the diagram above, here are the main steps to build a model server with BentoML:
- Implement the model logic: Write the Python class for your ML model. Define how to load it, perform predictions, and connect the APIs with your class methods.
- Create a Bento: Use the
bentoml buildCLI command to build the Bento from the model class you wrote. - Test the Bento: Run
bentoml serveto start the Bento server. It will listen to a port on your machine. Send REST requests with curl or Python to check if the server works correctly. - Build a Docker image: Run
bentoml containerizeto create a Docker image from your Bento. This step allows you to run the model server in any environment. - Deploy: Add your Docker image to your production environment. Your model can now receive inputs and return predictions in your application.
Advantages of BentoML
- Flexible and easy-to-use: As BentoML is a Python framework, you can package any machine learning logic you can think of. It provides ready-made classes to easily serve ML models.
- Multi-ML frameworks: You can integrate any Python package with BentoML. In other words, you can use any machine learning framework that supports Python, such as TensorFlow, Keras, Scikit-learn, PyTorch, and many more.
- Concurrent model execution: This framework supports loading multiple models or replicas of the same models on a single GPU.
- Integration: BentoML has an extensive list of supported tools. You can use ZenML to automate the creation of the model server, Spark for batch inference, import MLflow models, speed up the model inference with Nvidia Triton, and much more.
- Clear documentation: The documentation is easy to read, well-structured, and contains plenty of helpful examples.
- Monitoring: Every tool on this list produces Prometheus metrics. BentoML goes even further by supporting ArizeAI.
- LLM support: BentoML integrates with OpenLLM, a framework to operate Large Language Models. The same company developed both frameworks.
Drawbacks of BentoML
- Requires extra implementation: BentoML is designed for Python, so you need to write the code for loading models and making predictions yourself.
- Runs on Python: BentoML uses the Python runtime. However, you can use more efficient runtimes through their Python APIs such as ONNX. Unfortunately, it is still less efficient than TorchServe or TFX, which natively support high-performance runtimes.
Summary of BentoML
BentoML is your go-to solution if you want to serve ML models quickly. It is the easiest tool to use on our list. This framework really shines for teams that work with multiple ML frameworks but require a standardized process to build their model servers.
However, for companies that require best-in-class performance, BentoML might not be the best option as it exclusively runs on Python.
To learn more about this tool, read my BentoML concepts guide.
Triton Inference Server
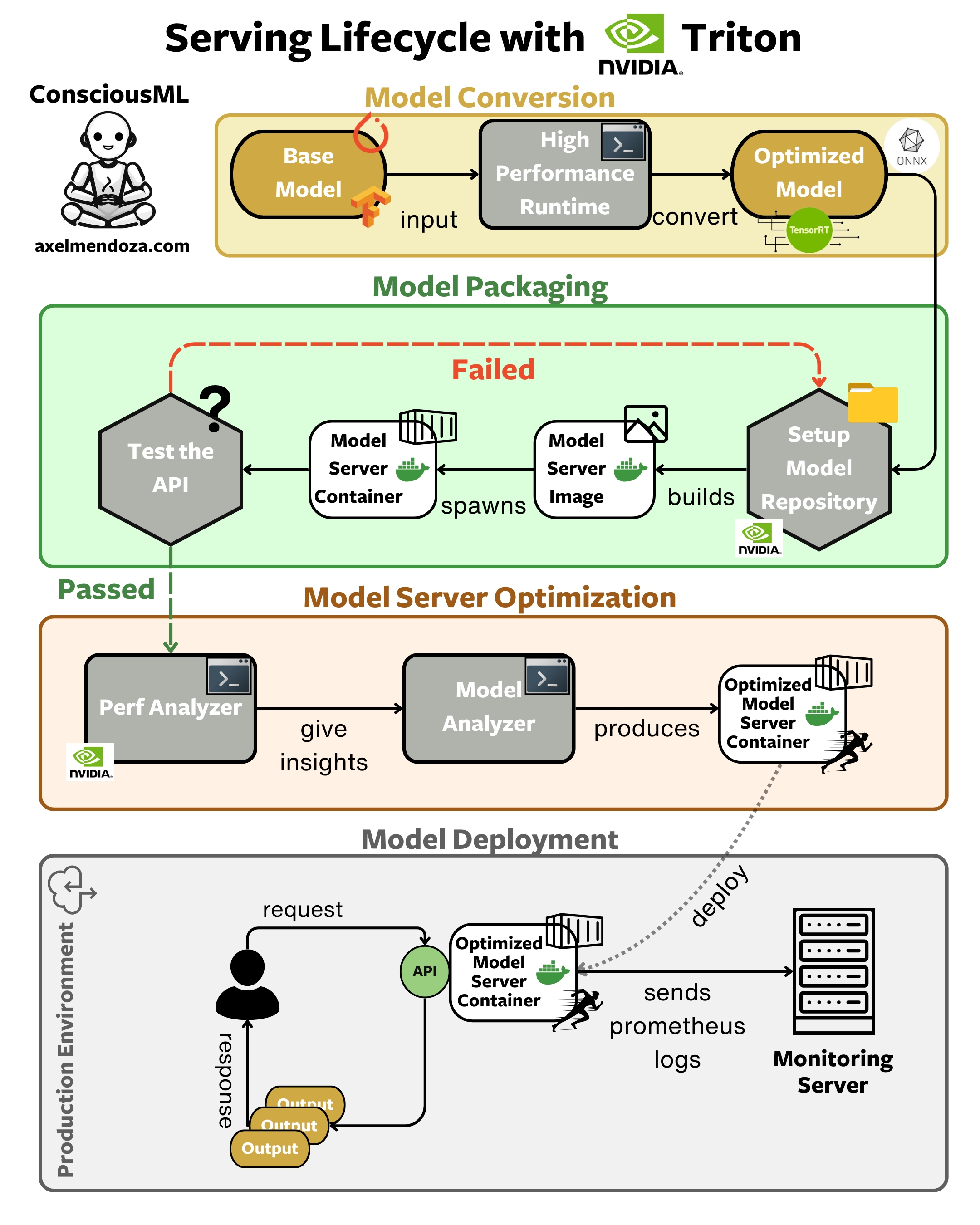
Triton Inference Server is the model serving runtime that provides the best performance on our list. Its robust architecture design allows for advanced optimizations and unmatched customization control over your models.
As shown in the flowchart above, here are the main steps to build and deploy a model server with Triton:
Model compatibility check: Verify that your model works with Triton’s supported backends like TensorRT or ONNX Runtime. If your model isn’t compatible, you’ll need to convert it or develop a custom backend.
Create model repository: Follow Triton’s directory structure by placing your model files in a subdirectory and create a
config.pbtxtfile to specify the configuration of your model.Launch Triton server: Use Docker to start the Triton server running your models. This containerization ensures your server can run in any environment supporting Docker.
Test the inference API: Send a request to the Triton server to ensure it’s working correctly. If you encounter issues, go back to your model repository setup and fix the problem.
Benchmark performance: Use Triton’s Perf Analyzer to measure your model’s performance. This step helps you understand your model’s baseline metrics such as inference time, hardware usage, and more.
Optimize performance: Use the Model Analyzer to perform a parameter search to find the optimal configuration for your model. This tool helps you squeeze the most performance out of your hardware.
Monitoring setup: Configure Prometheus to monitor your model’s performance metrics in production. This step is crucial to observe the key metrics of your server in production and react accordingly.
Advantages of Nvidia Triton
- Multi-ML frameworks: Triton supports every leading deep learning and machine learning framework.
- Concurrent model execution: Triton’s instance group configuration can be used to load multiple instances of a model on a single GPU.
- Advanced optimizations: Triton has many advanced features you won’t find anywhere else. For example, the sequence batcher feeds the inputs in ordered batches for stateful models. You can even pass tensors directly between models with the ensemble scheduler.
- Advanced monitoring: The Triton server provides more detailed Prometheus metrics than other tools we’ve listed.
- Advanced tools: Triton provides multiple utilities to improve the performance of your models:
- Model Analyzer improves your model’s performance by identifying the best Triton configuration settings for your hardware.
- Performance Analyzer enables debugging performance issues.
- Model Warmup loads your models and performs inference checks to ensure they meet performance standards.
- Documentation: Triton’s documentation is clear and well organized in comprehensive sections that regroup related content.
Drawbacks of Nvidia Triton
- Steep learning curve: Triton is the most challenging model-serving framework to work with because of its advanced features and customization capabilities. This means there’s a lot to learn, including several complex concepts on how the framework works.
- Hardware lock-in: Triton shines when running on high-end Nvidia GPUs. You might need to commit to expensive hardware to get the most out of this framework.
Summary of Nvidia Triton
Triton is the best model serving runtime for teams that want to get the most out of their GPUs. Its architecture provides best-in-class concurrent model execution, which is a huge plus. Especially for real-time ML products relying on large deep-learning models.
Unfortunately, your team will need strong software skills to develop, monitor, and maintain Triton servers. In other words, it is important to consider the implementation costs needed to operate with this framework.
Model Serving Runtimes Feature Table
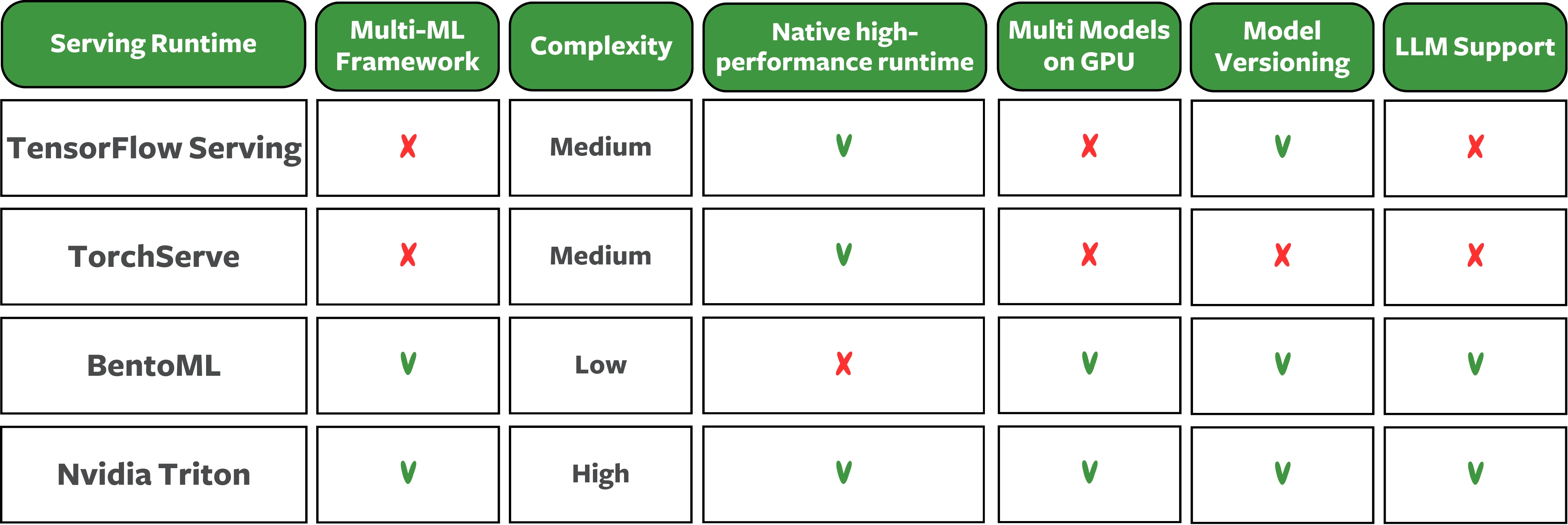
Conclusion
A Model Server handles API requests and responds with model predictions. Building such a component is not an easy task.
Model Serving Runtimes help you build, monitor, and optimize model servers. They use techniques to make model inference faster, offer built-in monitoring, and simplify creating a Docker image for your model.
Real-time ML applications and large data batch pipelines need low inference latency and the ability to handle multiple requests simultaneously to deliver predictions in time. Serving runtimes shine particularly in these scenarios.
TensorFlow Serving, TorchServe, BentoML, and Triton Inference Server each offer unique features suited for different needs.
Choosing the right serving runtime depends on your specific requirements, including ML-framework support, performance needs, existing MLOps stack, and your team’s software skills.
Selecting the right tool is essential for your ML projects to succeed. Besides the information in this article, try a simple proof of concept to ensure it fits your needs. Good luck productionizing ML!