
I'm a Senior MLOps Engineer with 6+ years of experience building production-ML systems.
I write long-form articles on MLOps to help you build too!
Do you want to build a real-time machine-learning application? Or perhaps you are searching for ways to reduce cloud costs? This article is for you, as we will discuss a key component of MLOps for building optimized model servers.
As deep learning models have grown larger over the years, simple setups like Flask+Docker no longer meet the needs of demanding tasks such as real-time machine learning and large batch processing pipelines.
Fortunately, Model Serving Runtimes, such as TensorFlow Serving, TorchServe, BentoML, and Triton Inference Server, have been designed specifically to address this issue.
By the end of this article, you will fully understand:
- What is a Model Server?
- Model Serving Runtimes and their interaction with Model Servers.
- The reasons why you need a serving runtime.
- When are serving runtimes not necessary?
- How to scale your machine learning models?
Let’s start by understanding the preliminaries: the Model Server.
What is a Model Server?
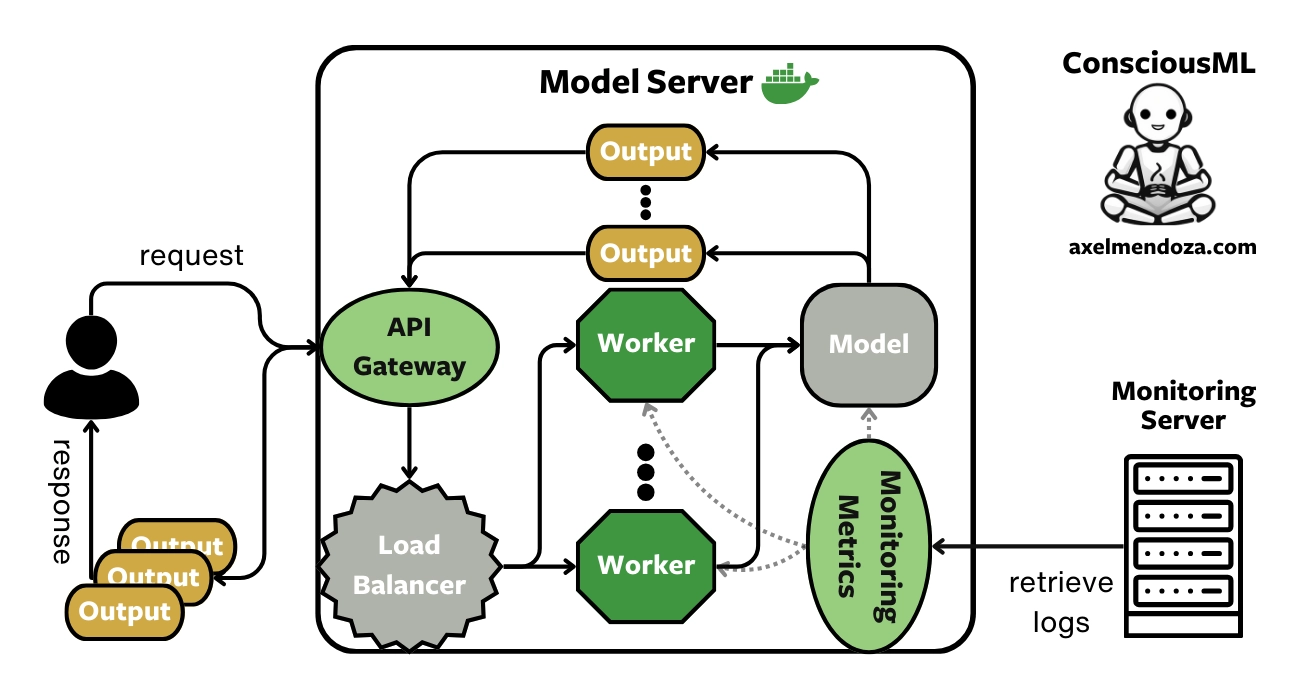
A Model Server is a Docker image containing one or more machine learning models, exposing APIs to handle incoming requests (data), perform inference, and serve the model predictions.
This MLOps component is key to understand to get a full grasp of the model serving big picture. Read more in our model server overview.
What is a Model Serving Runtime?
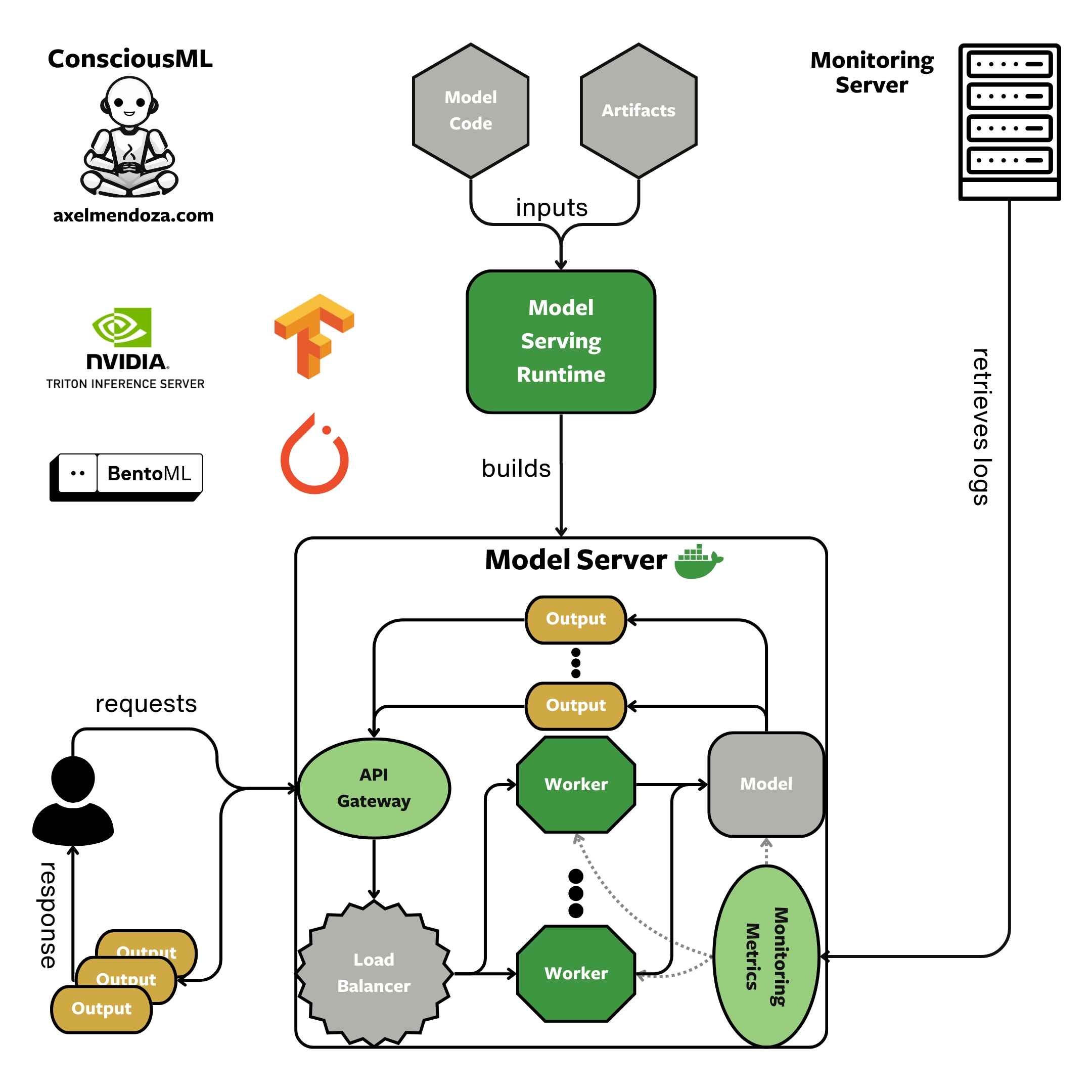
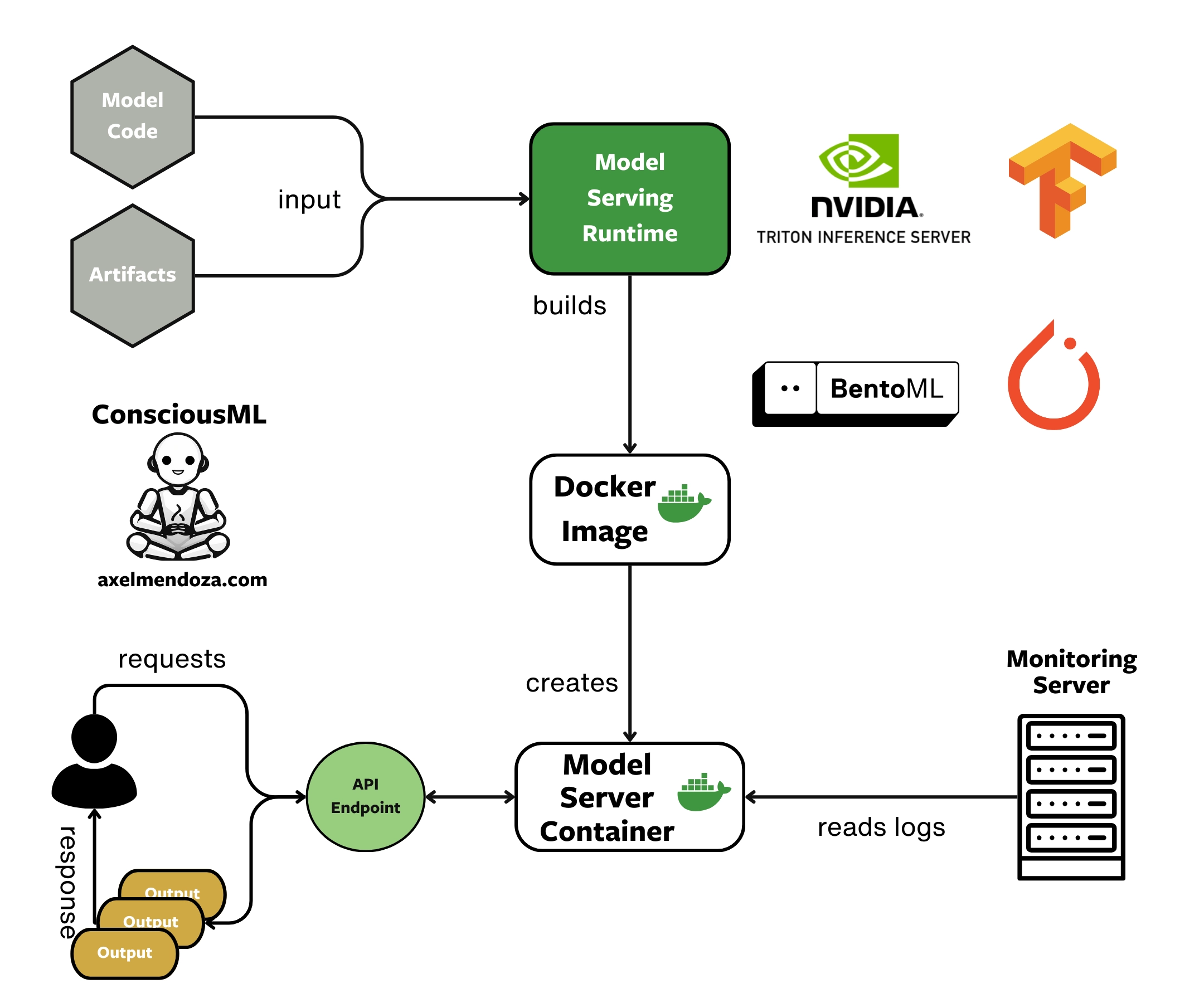
Model Serving Runtimes are tools designed to create Model Servers optimized for ML workfloads. It streamline the process of building APIs optimized for ML inference. With this strategy, we can create Docker containers from the image and deploy them in production to receive data and provide predictions.
The diagram above illustrates the process of building an efficient Model Server by using a serving runtime, the model code, and model artifacts. Then, users can make API requests to the server and receive model outputs as responses.
Benefits of a Model Serving Runtime
Optimized for model inference: Tools like TorchServe offer multiple optimization techniques, thus achieving better performance and faster response times.
Reduces hardware cost: Using your hardware efficiently means you need fewer machines to run your AI application, which lowers the cost of your infrastructure.
Out-of-the-box monitoring: All the serving runtimes we will evaluate generate Prometheus metrics by default. This makes monitoring hardware resources and model performance easier.
Simplified packaging: These frameworks provide tools that simplify building optimized Docker images for your models.
Ready-made APIs: These tools support a wide range of input and output types for your machine-learning APIs, such as Text, Image, Dataframes, JSON, and more.
When do you Need a Model Serving Runtime?
Serving runtimes thrive in the context of heavy ML workflows, such as:
Real-time ML: In this scenario, your application must process multiple simultaneous requests in a limited time frame. As serving runtimes produce model servers optimized for ML workflows, they can process requests concurrently and use multiple optimization techniques to reduce latency and increase throughput.
High Volume batch pipelines: The same principle applies to batch pipelines: if your pipeline needs to handle a large amount of data before the next day, you will benefit from using serving runtime.
Reducing cloud costs: Serving runtimes help reduce cloud costs by optimizing resource usage, which decreases the need for extra hardware.
Reasons you don’t Need a Model Serving Runtime
Batch processing: These tools shine in real-time applications. However, you might not need such a complex solution if the predictions can be computed in a batch pipeline triggered on a schedule.
Learning curve: Model serving runtimes usually require a lot of engineering effort. You will need to spend a lot of time understanding how to implement the optimal solution to serve your models.
Low traffic: If your model does not need to be scaled because of its fast inference or low number of requests, the benefits of a serving runtime may not justify the required technical effort.
How to Scale your Machine Learning Models?
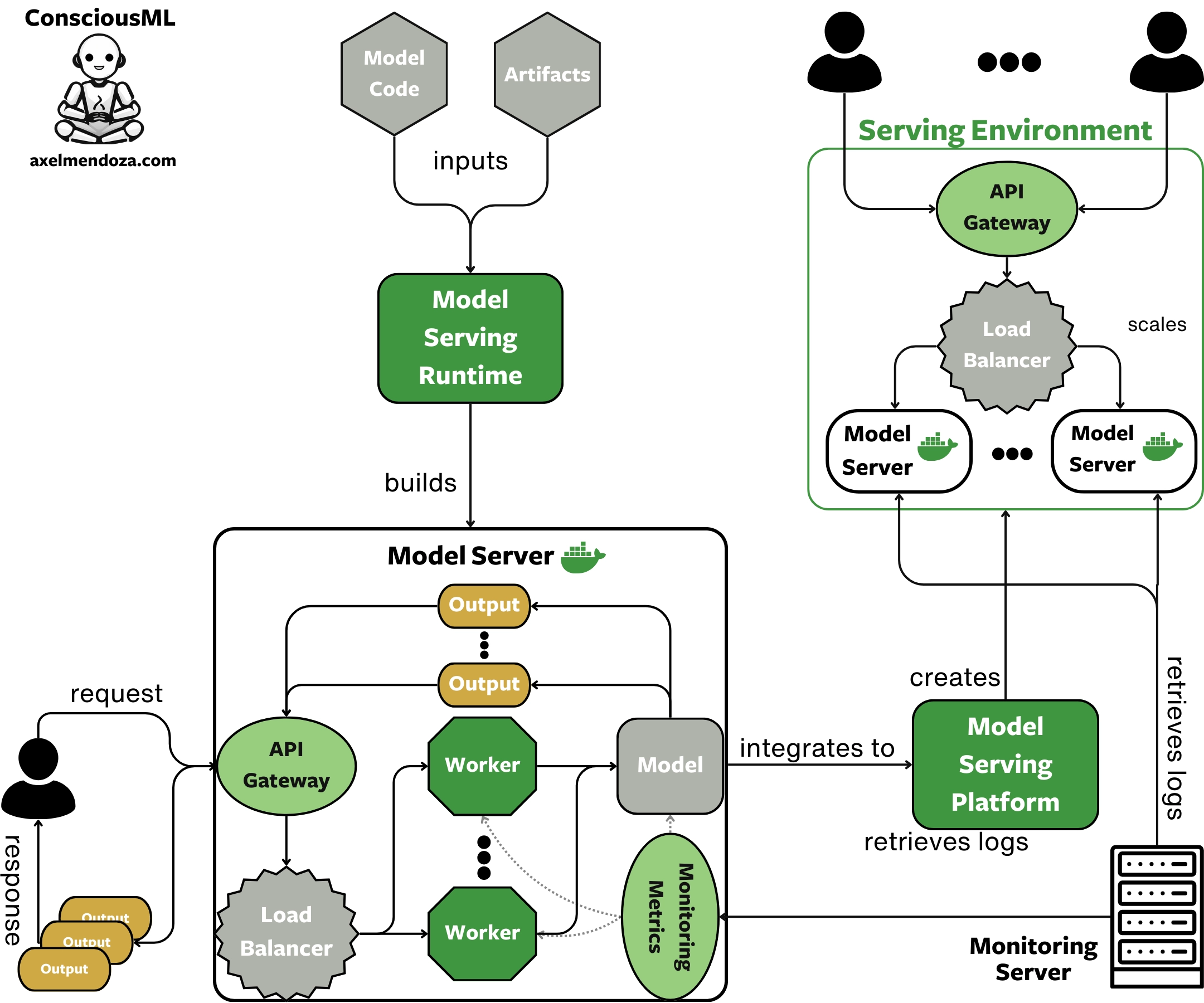
Using a Model Serving Runtime optimizes your model inference time, thus handling more requests. However, for most scaling scenarios, one model server instance is not enough to handle a large number of simultaneous requests.
The solution is to integrate your model server into a Model Serving Platform to dynamically scale the number of model servers in response to incoming traffic. Tools like KServe are examples of serving platforms. They manage the infrastructure that deploys and scales models, responding to varying traffic without manual intervention.
When a serving platform detects a traffic spike, it will spawn one or multiple model servers, each with its dedicated hardware, to distribute the requests across instances. When the traffic goes down, the model server instances are dismissed to save on cloud costs.
Best Model Serving Runtimes
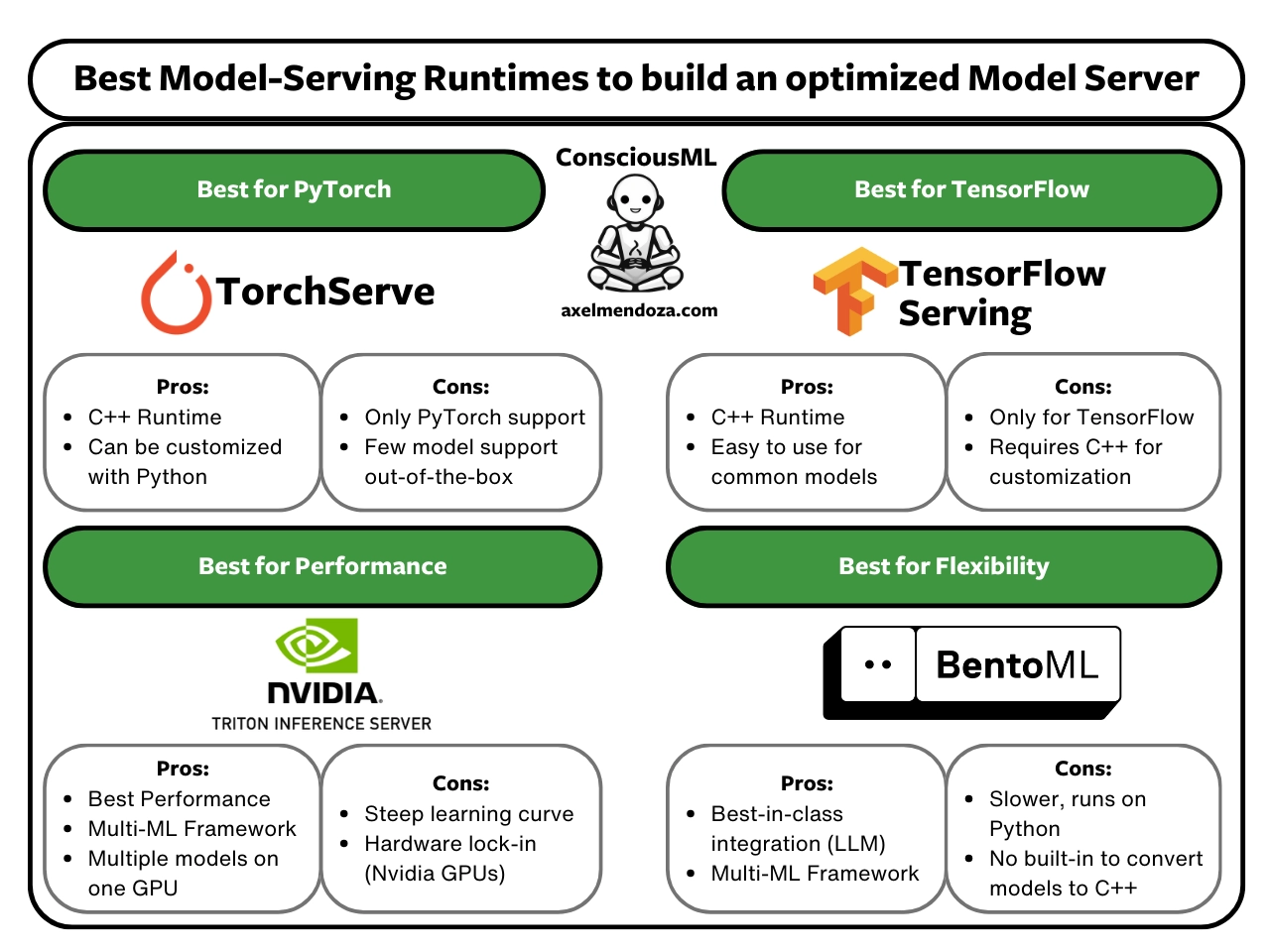
Choosing a Model Serving Runtime is not an easy task. There so many criteria to take into account such as framework and runtime support, infrastructure integration, inference optimizations, learning curve and monitoring support.
This is exactly why we wrote our best model serving runtimes guide, where we provide guidance on how to choose among the leading frameworks like TensorFlow Serving, TorchServe, BentoML, and Triton Inference Server.
Read our guide to understand the main criteria for choosing a serving runtime. It includes an in-depth comparison of the previously mentioned tools, their pros and cons, and the team target.
Conclusion
A Model Server is a crucial part of machine learning applications that handles API requests and returns model predictions.
Model Serving Runtimes are the perfect solution to build, monitor, and integrate highly optimized model servers. They use optimization techniques to speed-up the inference of your models, provide out-of-the-box monitoring, and simplify building a Docker image or your model.
For demanding ML workloads, such as real-time applications or high-volume batch pipelines, using a serving runtime is important as it reduces inference latency to serve the prediction in time.
However, in these scenarios, one model serving instance is usually not enough. Integrating your model servers into a Model Serving Platform is and optimal solution for deploying and scaling your ML models.
MLOps is becoming a more mature field day by day. However, it is far from solved. We hope that providing a clear explanation of key MLOps concepts will help you in your journey creating ML products!