
I'm a Senior MLOps Engineer with 6+ years of experience building production-ML systems.
I write long-form articles on MLOps to help you build too!
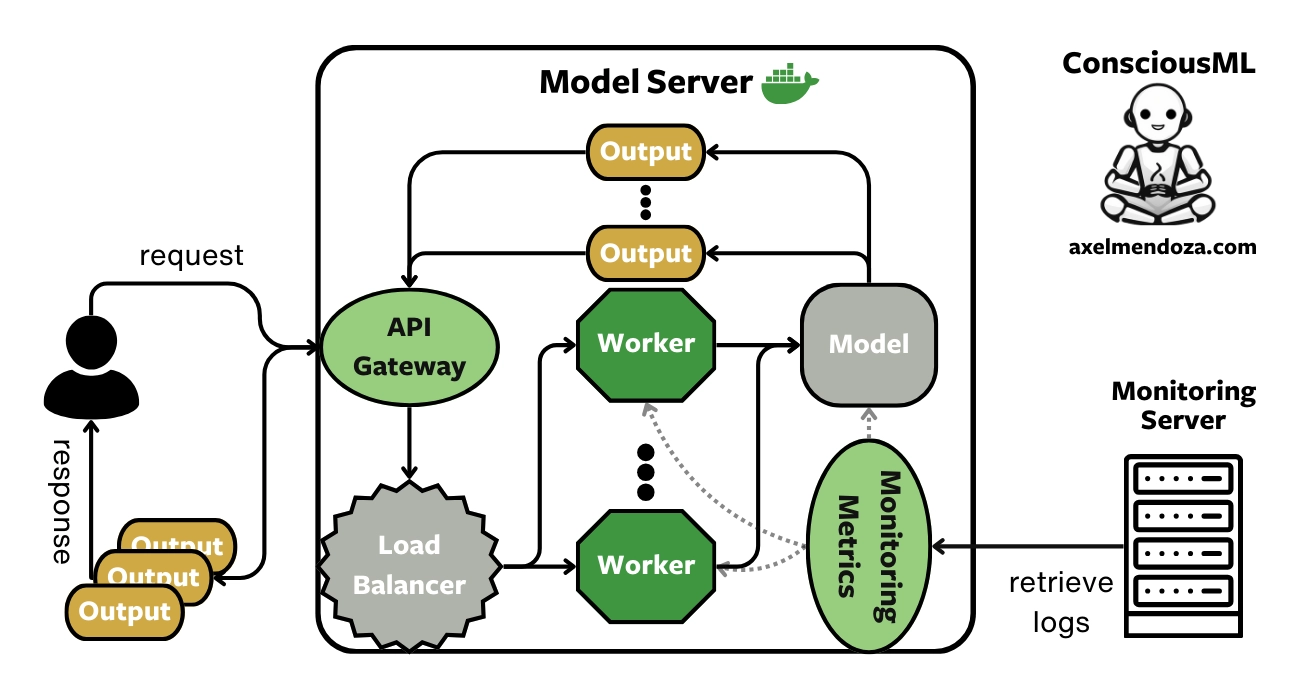
Most machine learning products need a model server, a component that receives API requests and responds with predictions. Unfortunately, the good old days of simple Flask+Docker setups are long gone.
Deep learning models have consistently grown in size over the years. To serve them efficiently, we need ML-optimized model servers more than ever.
After reading this guide, you will fully understand:
- Model servers and their architecture.
- The benefits of using a model server.
- The reasons you might not need one.
- Model serving runtimes and their interaction with model servers.
What is a Model Server?
A Model Server is a Docker image containing one or more machine learning models, exposing APIs to handle incoming requests (data), perform inference, and serve the model predictions.
A Key Component of the MLOps Lifecycle
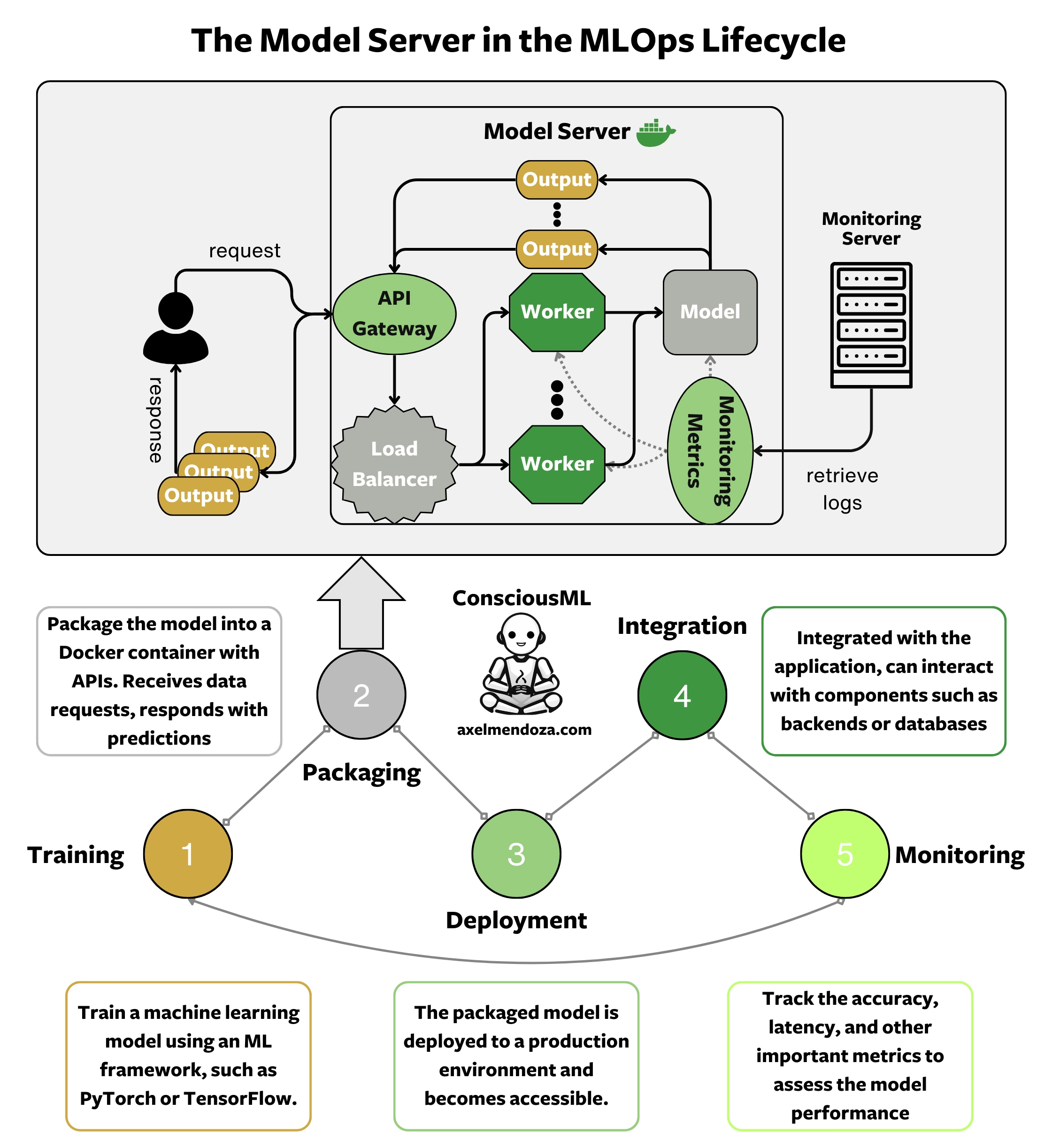
First, let’s review the MLOps lifecycle to understand where does model servers integrate in this scheme. A typical MLOps workflow involves the following steps:
- Training: We train a machine learning model on a specific task using an ML framework, such as PyTorch or TensorFlow.
- Packaging: After training, we package the model into a format suitable for deployment.
- Deployment: The packaged model is then deployed to a production environment and becomes accessible.
- Integration: The deployed model is integrated with the application, ensuring it can receive input data and output predictions.
- Monitoring: Once deployed, we track the accuracy, latency, and other important metrics to assess the model performance.
A Model Server comes into play during the packaging process. Once an ML model has been trained, it must be packaged in a format that can be deployed in various environments, such as a Docker image.
The Model Server Architecture
A Model Server contains the following components:
- API Gateway: The entry point for all requests. It delegates each request to the load balancer.
- Load Balancer: Distributes incoming requests across multiple workers to enable concurrent processing.
- Worker: The component that processes the requests. Each worker feeds the input data into the machine learning model to generate predictions.
- Machine Learning Model: The core element that performs the predictions. It has been trained, packaged, and deployed specifically for this purpose.
- Monitoring Endpoint: This component reports metrics related to the performance of the machine learning model, such as predictions, input data distribution, or latency.
As you can see, Model Servers are complex systems that orchestrates multiple sophisicated entities. Building one from scratch is not the best approach. Fortunately, there are tools specifically designed for this that we will discuss in a later section.
The Benefits of Using a Model Server
Using a Model Server, as opposed to integrating a model directly into a repository, has all the advantages of the micro-services architecture:
- Ease of deployment: The server can be deployed on any platform, whether on the cloud or on-premise.
- Better Integration: Model servers simplify integration with other services. Accessibility through an API eliminates the need to install dependencies or requirements to interact with the model.
- Flexibility: It isolates the model logic from the other services. When deploying a new model version, changing the logic of the services using the Model Server is not required, as they use the same interface for inputs and outputs.
- Separation of ML dependencies: It isolates machine learning dependencies from the rest of your application stack. This is crucial as ML frameworks are usually far from lightweight.
Reasons not to Use a Model Server
In some scenarios, using a Model Server might not be necessary:
- Simple Workflow: If you do not need dedicated hardware and are using the model in one location, you can run it directly on the same instance that handles your pipeline.
- Batch processing: You might not need a Model Server if a scheduled batch pipeline can compute the predictions and complete the run in time when you need the data.
- Learning curve: Building a Model Server often takes a lot of engineering work. You will need to spend much time learning how to serve your models best.
- Low traffic: If your model handles input quickly and gets few simultaneous requests, using a Model Server may not be worth the effort.
How to Build a Model Server?
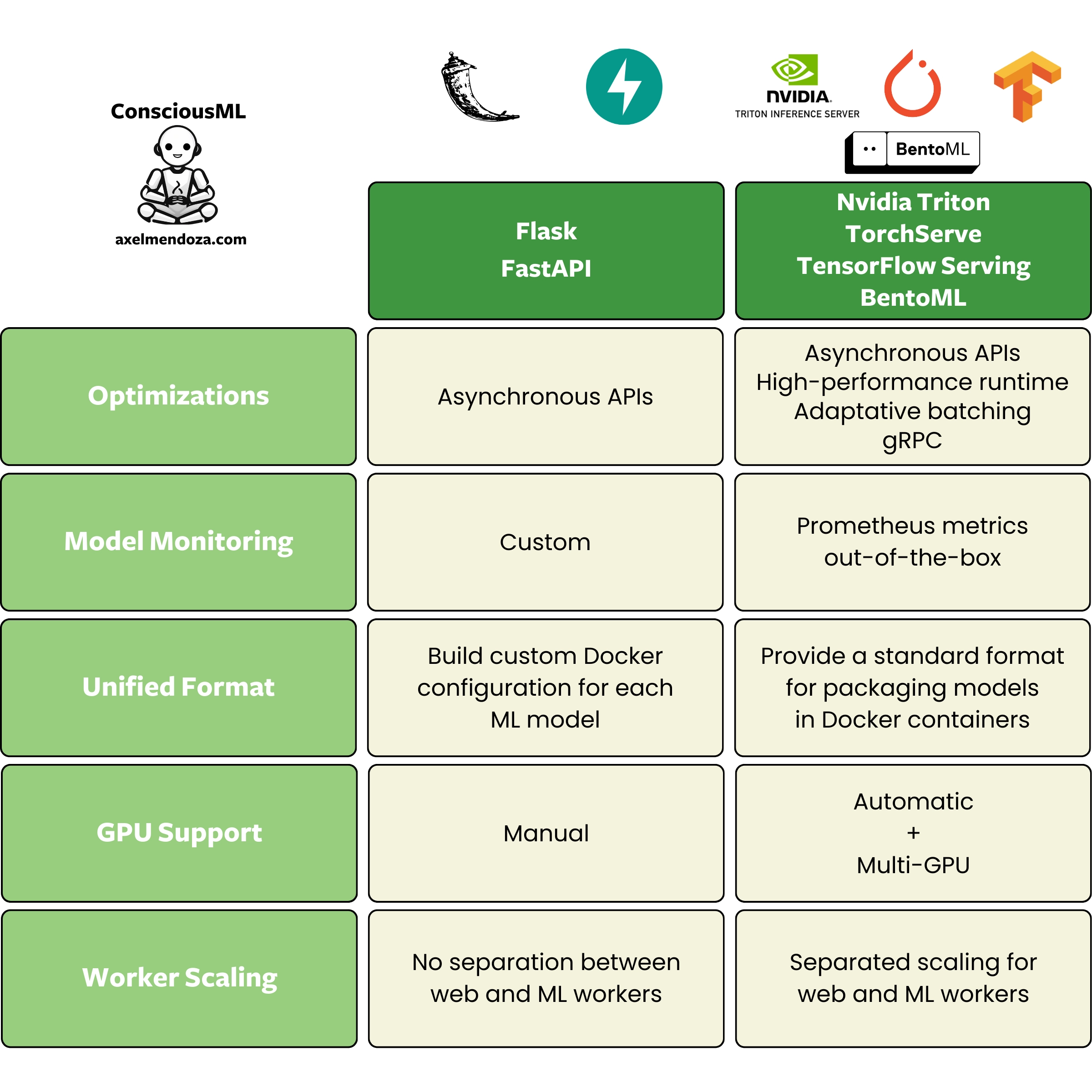
Using Docker with a web framework is the most straightforward way to create a Model Server. For simple workflows, this solution will do the job. You can deploy your model in a container that exposes API endpoints, taking input data and responding with predictions.
However, web frameworks such as Flask and FastAPI are not optimal to serve machine learning models, particularly for high traffic and low latency requirements.
The main drawbacks of using Flask and Docker are the following:
- Lack of a unified format: You need to create a custom Docker configuration and Python logic for every machine learning model.
- Model monitoring: Traditional web frameworks are not designed for ML workflows, so your containers will not automatically serve monitoring metrics out of the box.
- Inference performance: ML workloads are often compute and memory-intensive, requiring a different architecture than web applications for which Flask and FastAPI were designed.
- GPU support: Flask and Docker setups do not automatically support GPUs for machine learning tasks. You must manually configure them to leverage GPU acceleration, which adds complexity.
- Scaling: There is no separation between the scaling of web request workers and model inference workers.
Fortunately, Model Serving Runtimes are tools specifically designed to address these issues.
What is a Model Serving Runtime?
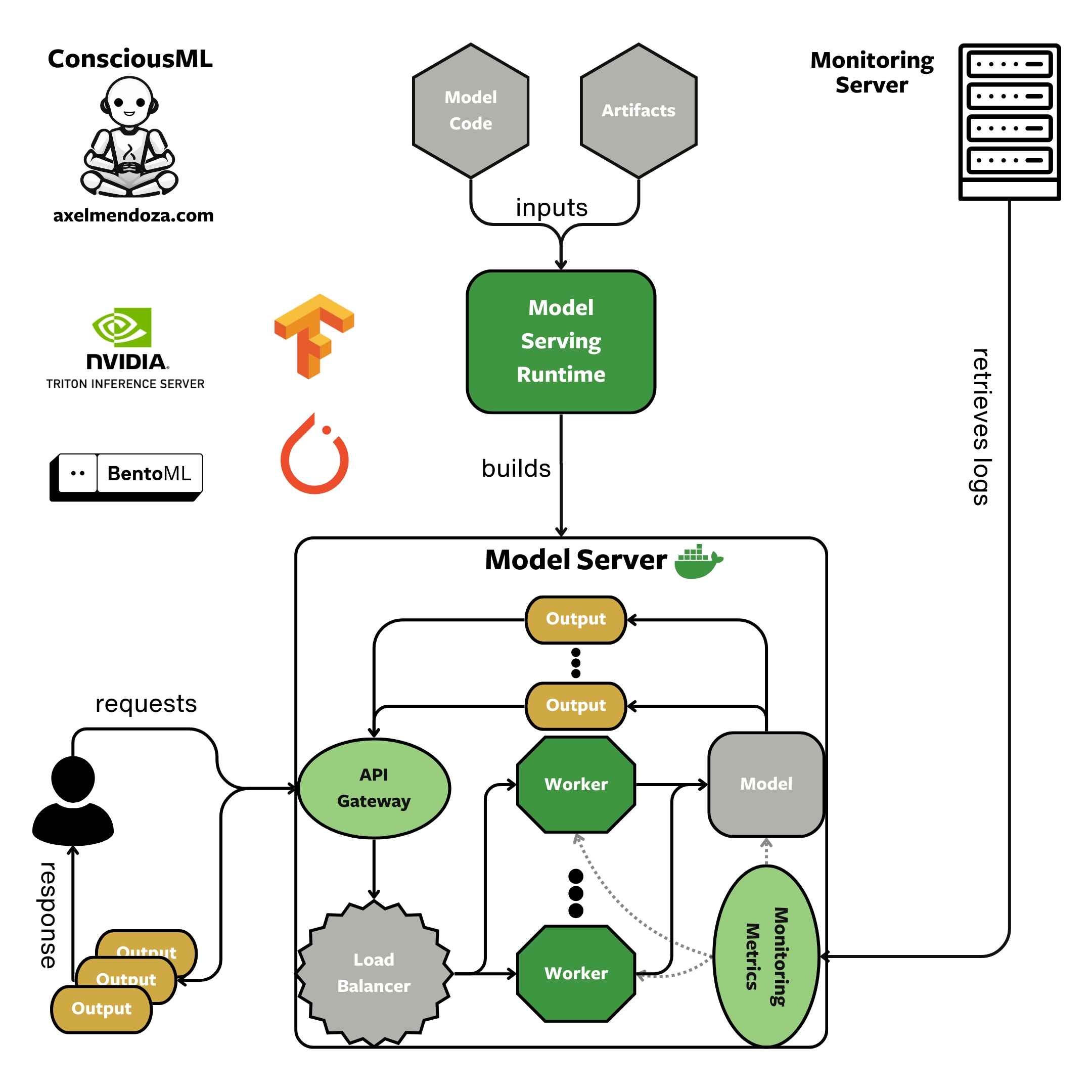
A Model Serving Runtime packages a trained machine learning model in an ML-optimized Docker container and builds APIs. The model is then ready for production, allowing it to receive data and provide predictions.
Read our model serving runtimes overview to learn:
- The benefits of Model Serving Runtimes.
- The reasons you might not need one.
- How to scale your ML models?
Tools like TorchServe, TensorFlow Serving, Triton Inference Server and BentoML, belong to this category.
Checkout our best model serving runtimes article to know which one best suits your needs!
Conclusion
A Model Server is a key component of machine learning applications that receives API requests and serves model predictions.
You almost always need to use a inference optimized server for real-time applications, high data volume batch pipelines, or implementing a micro-service architecture.
An ML-optimized Model Server is a complex system with a sophisticated architecture that orchestrates the interactions of multiple components, such as a load balancer, workers, ML models, and monitoring endpoints.
Model-serving runtimes are the perfect solution to build, monitor, and integrate highly optimized model servers.
Whether you are starting or improving your systems, I hope this article will help you make optimal decisions about using Model Servers in your work.