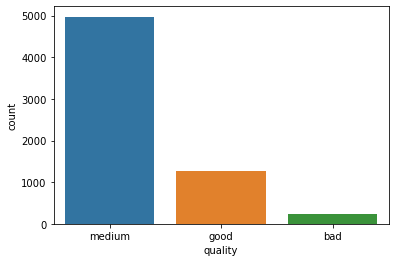During this experiment, we will train a K-nearest neighbors model on physicochemical data to predict the quality of a red or white wines.
If you haven’t already, feel free to read the previous article of this series.
The KNN will be implemented from scratch using Pytorch along with clear explanation of how the model works. Exploratory data analysis techniques are also discussed in the last section of the notebook.
import osimport syssys.path.append('..')import torchimport numpy as npimport pandas as pdimport seaborn as snsimport statsmodels.api as smimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import classification_reportfrom sklearn.preprocessing import StandardScalerfrom sklearn.preprocessing import LabelEncoder
<matplotlib.axes._subplots.AxesSubplot at 0x2969e19ed08>
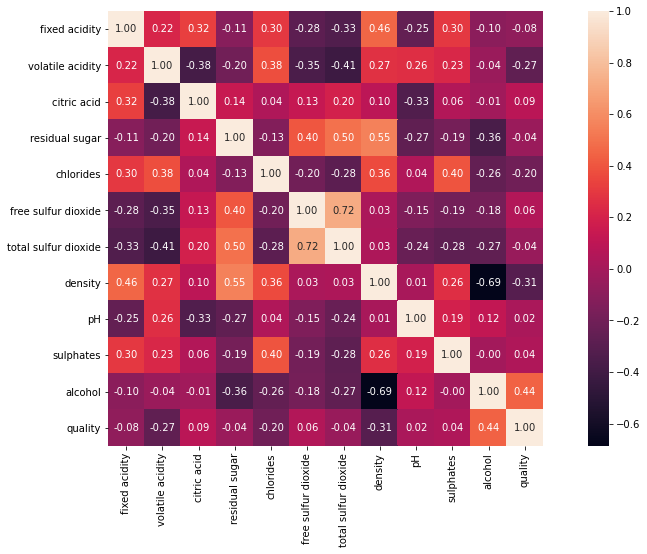
The features most correlated with the quality are:
alcohol
density
volatile acidity
Most of the features are very highly correlated to each other. We will try to select the best features to avoid redundancies using backward elimination further in the notebook.
<matplotlib.axes._subplots.AxesSubplot at 0x2969ef0e448>
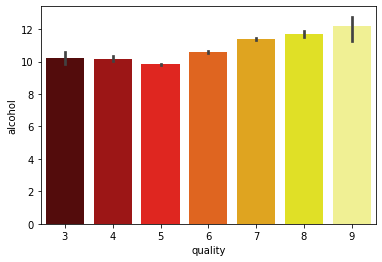
Wines between 7 and 9 quality have a higher alcohol values, we will choose this range for the good wines. Thus, it looks appropriate to divide the quality label into low, medium and good wines.
<matplotlib.axes._subplots.AxesSubplot at 0x2969e3b9f08>
Isolate features from the target
Feature scaling is mandatory when using a K-nearest neighbors model. The KNN algorithm has a distance decision based approach to regress or classify an input. In fact, if some features have higher values than other, they will contribute more in the overall distance calculation thus biasing the outcome.
X = wines.iloc[:, :-1].to_numpy()y = wines.iloc[:, -1].to_numpy()
Convert category to integer
y = LabelEncoder().fit_transform(y)
Create the Training Split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)scaler = StandardScaler() X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)# Convert data to pytorch tensorX_train = torch.from_numpy(X_train)X_test = torch.from_numpy(X_test)y_train = torch.from_numpy(y_train)y_test = torch.from_numpy(y_test)
We will use Pytorch for this experiment
K-Nearest Neighbors
The K-nearest neighbors classifier looks at the \(K^{th}\) closest points in the training set of an input \(x\) counts how many members of each class are present and returns the empirical fraction as the estimate.
where \(c\) is the class and \(N_K\) are the closest sample of \(\boldsymbol{\text{x}}\) in \(D\).
def knn(sample, X, y, k_neighbors=10):"""Instance of K-Nearest Neigbhors model Args: X: A torch tensor for the data. y: A torch tensor for the labels. k_neighbors: An integer for the number of nearest neighbors to consider. """ sample = sample.unsqueeze(1).T# Compute the distance with the train set dist = (X - sample).pow(2).sum(axis=1).sqrt()# Sort the distances _, indices = torch.sort(dist) y = y[indices]# Get the Kth most similar samples and return the predominant classreturn y[:k_neighbors].bincount().argmax().item()
def train_knn(X_train, X_test, y_train, y_test, k_neighbors=1):"""Trains a K-Nearest Neigbhors model Args: X_train: A torch tensor for the training data. X_test: A torch tensor for the test data. y_train: A torch tensor for the training labels. y_test: A torch tensor for the test labels. k_neighbors: An integer for the number of nearest neighbors to consider. """# Allocate space for the prediction y_pred_test = np.zeros(y_test.shape, dtype=np.uint8) y_pred_train = np.zeros(y_train.shape, dtype=np.uint8) X_train_c = X_train.clone()# Predict on each sample of the train and testfor i inrange(X_test.shape[0]): y_pred_test[i] = knn(X_test[i], X_train, y_train, k_neighbors=k_neighbors) y_pred_test = torch.from_numpy(y_pred_test).float()return y_pred_test
pred_test = train_knn(X_train, X_test, y_train, y_test, k_neighbors=1)print(classification_report(y_test, pred_test))# Save data for future visualizationX_train_viz = X_trainX_test_viz = X_testy_train_viz = y_trainy_test_viz = y_test
Dropping column residual sugar, pvalue is: 0.6594184624811075
Dropping column total sulfur dioxide, pvalue is: 0.40799376734207193
Dropping column total sulfur dioxide, pvalue is: 0.16949863758492337
Feature selection based on p-value made the performance worse. From 83% to 77%. We tested with a value \(k \in [1, 10]\) and the best result is given \(k = 1\).
Let’s try to select all the feature that has more than \(0.10\) correlation with the target.
Same result as backward elimination. Sometimes all the features are relevant for a given model.
Conclusion
The K-nearest neighbors algorithm is a simple but rather effective approach in some contexts. The KNN method has no training step which is very handy when we have an increasing amount of data. In fact, it is not required to train the KNN model.
However, KNN is not a model to pick when the data has a high dimentionality. Computing the neighbor distances accross a large number of dimension is not effective. This phenomena is also called the “curse of dimensionality”. The KNN model is also uneffective when dealing with outliers.
Want to keep learning ? You can jump right in my next article on Polynomial Regression.
Stay in touch
I hope you enjoyed this article as much as I enjoyed writing it!
Feel free to DM me any feedback on LinkedIn or email me directly. It will be highly appreciated.
That's what keeps me going!
Subscribe to get the latest articles from my blog delivered straight to your inbox!
About the author
Axel Mendoza
Senior MLOps Engineer
I'm a Senior MLOps Engineer with 6+ years of experience building production-ML systems.
I write long-form articles on MLOps to help you build too!