This blog post is about implementing Support Vector Machines from scratch using CVXOPT. We will go through the math behind the SVM method and test out the kernel RBF and linear kernel on generated data.
If you haven’t already, feel free to read the previous article of this series.
import osimport torchimport numpy as npimport matplotlib.pyplot as pltfrom cvxopt import matrix as cvxmatfrom cvxopt import solvers as solverfrom sklearn.datasets import make_blobsfrom sklearn.preprocessing import StandardScaler
def generate_data(n_samples=200, n_features=2, centers=2, center_box=(-15., 15.), cluster_std=1.):"""Generates the clusters for testing linear SVMs Args: n_samples: An integer for the number of data points to be generated. n_features: An integer for the number of the columns in the output data. centers: An integer for the number of cluster to generate. center_box: A tuple of float for the location of the clusters. cluster_std: A float that controls the standard deviation of the clusters. """ X, y = make_blobs(n_samples=n_samples, n_features=n_features, centers=centers, center_box=center_box, cluster_std=cluster_std) y[y ==0] =-1 y = y.astype(float) st = StandardScaler() X_s = st.fit_transform(X)return X_s, y
X, y = generate_data()
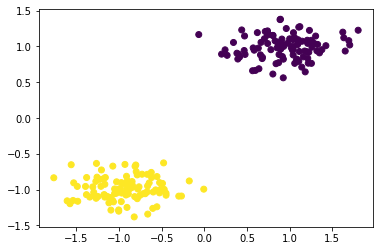
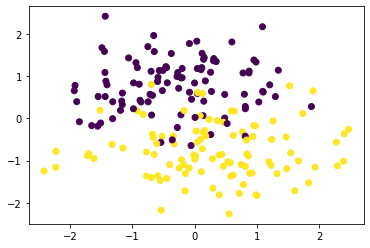
plt.scatter(X[:, 0], X[:, 1], c=y)
<matplotlib.collections.PathCollection at 0x16c4dd86448>
Here are two linearly separable clusters that we will use to test the Hard Margin SVM method.
Support Vector Machines
The Kernel Trick
First let’s define the kernel trick to understand the magic behind SVMs. A kernel function \(\kappa(\boldsymbol{x}, \boldsymbol{x^{'}})\) is a measure of similarity between two objects \(\boldsymbol{x}, \boldsymbol{x^{'}} \in \chi\) where \(\chi\) is an abstract space of higher dimension. Let’s assume that we have \(\boldsymbol{X}\) a non-linearly separable data. We would like to transform the data into a higher dimensional space to make it linearly separable. Let us define \(\phi\) a function that maps the data into a higher dimensional space. A classical approach would be to compute \(\phi(\boldsymbol{X})\) but this transformation may be very computationally heavy. Instead we use the kernel trick.
The kernel trick method stands for calculating the relationship of data in higher dimension without actually transforming the whole data. The kernel trick reduces the amount of computation required for kernelized algorithms. The main idea is, instead of computing \(\phi(\boldsymbol{X})\), we will compute the dot product \(\phi(\boldsymbol{X}_i)^\top\phi(\boldsymbol{X}_j)\) for all the components of \(\boldsymbol{X}\). In other words, we will know the relationship of the data in higher dimension, without ever computing the transformation of the whole data.
The kernel function is defined as: \[\begin{align}
\kappa(\boldsymbol{x}, \boldsymbol{x^{'}}) = \phi(\boldsymbol{x})^\top \phi(\boldsymbol{x^{'}})
\end{align}\]
The kernel function has the following properties: \[\begin{align}
\kappa(\boldsymbol{x}, \boldsymbol{x^{'}}) &\in \mathbb{R} \\
\kappa(\boldsymbol{x}, \boldsymbol{x}^{'}) &= \kappa(\boldsymbol{x}^{'}, \boldsymbol{x}) \\
\kappa(\boldsymbol{x}, \boldsymbol{x^{'}}) &\geq 0 \\
\end{align}\] There is a multitude of different kernels such as the linear kernel: \[\begin{align}
\kappa(\boldsymbol{x}, \boldsymbol{x^{'}}) = \boldsymbol{x}^\top \boldsymbol{x}^{'}\\
\end{align}\] The polynomial kernel: \[\begin{align}
\kappa(\boldsymbol{x}, \boldsymbol{x^{'}}) = \left(\boldsymbol{x}^\top \boldsymbol{x^{'}} + r\right)^d
\end{align}\] And the kernel RBF: \[\begin{align}
\kappa(\boldsymbol{x}, \boldsymbol{x^{'}}) = \exp\left(-\frac{|| \boldsymbol{x} - \boldsymbol{x^{'}} ||^2}{2\sigma^{2}}\right)
\end{align}\] where \(r\) is the coefficient of the polynomial and \(d\) its degree, while \(\sigma\) is known as the bandwith of the radial basis function (RBF).
Hard Margin Classifier
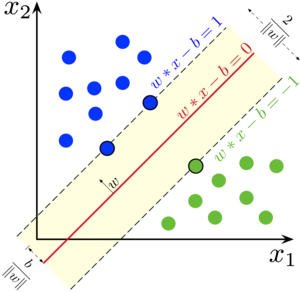
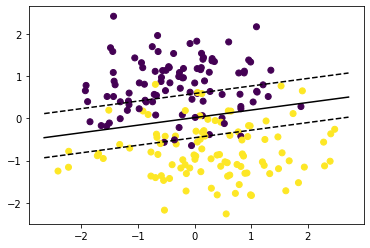
Support vector machines were originally designed for binary classification but can be extended to regression and multi-class classification. SVMs are not probabilistic models, their output is a raw prediction. We will only discuss how SVMs work for classification. Let’s get the basic intuition with the help of the following figure.
SVMs separate the data in two classes using a hyperplane. The distance between the dotted hyperplanes and the hyperplane at the center is known as margin. A margin is passing by one or multiple points, these points are known as support vectors. Any point above the red hyperplane will be classified as \(1\) respectively \(-1\) for the points below the hyperplane. In order to predict on an input sample \(\boldsymbol{x}\), we compute the linear equation: \[\begin{align}
f(\boldsymbol{x}) &= \boldsymbol{w}^\top \boldsymbol{x} + b \\
\hat{y} &=
\begin{cases}
\;\;\;1 & \text{if} \quad f(\boldsymbol{x}) \geq 0 \\
-1 & \text{otherwise}
\end{cases}
\end{align}\]
SVMs try to maximize the margin when separating the data. This fact plays a role in the generalization of SVM models. We can find the value of the margin by solving the equation: \[\begin{align}
\boldsymbol{w}^\top (\boldsymbol{x}_2 - \boldsymbol{x}_1) &= 2 \\
\frac{\boldsymbol{w}^\top}{||\boldsymbol{w}||} (\boldsymbol{x}_2 - \boldsymbol{x}_1) &= \frac{2}{||\boldsymbol{w}||}
\end{align}\]
In other words, we need to solve the optimization problem known as primal: \[\begin{align}
&\min_{\boldsymbol{w}, b}\frac{1}{2}||\boldsymbol{w}||^2 \\
&\text{s.t} \quad y_i(\boldsymbol{w}^\top \boldsymbol{x}_i + b) \geq 1 \\
&\text{s.t} \quad \forall i \in \{1, \dots, N\}
\end{align}\]
The reason we minimize \(||\boldsymbol{w}||^2\) instead of \(||\boldsymbol{w}||\) is that minimizing the second option is non-convex. The condition ensures that all samples are on the right side of the hyperplane. Note that this classifier does not allow any misclassification and is known as hard margin classifier.
Primal form to Dual form
The primal form is can be transformed to the dual for which is more suited for implementation. We can use the generalized Lagrangian to get the dual form that has more feasible constrains: \[
\begin{align}
&\min_{\boldsymbol{x}, b}L(\boldsymbol{x}, b, \boldsymbol{\sigma}) \\
&= \frac{1}{2}||\boldsymbol{w}||^2 \\
&- \sum_{i=1}^{N} \sigma_i y_i(\boldsymbol{w}^\top \phi(\boldsymbol{x}_i) + b - 1)
\end{align}
\]
We also need to satisfy the KKT conditions, such as: \[
\begin{align}
&\frac{\partial L}{\partial \boldsymbol{w}} = \boldsymbol{w} - \sum_{i=1}^{N} \sigma_i y_i\phi(\boldsymbol{x}_i) = 0 \\
&\Rightarrow \boldsymbol{w} = \sum_{i=1}^{N} \sigma_i y_i\phi(\boldsymbol{x}_i) \\
&\frac{\partial L}{\partial \boldsymbol{b}} = -\sum_{i=1}^{N}\sigma_i y_i = 0 \\
&\Rightarrow \sum_{i=1}^{N}\sigma_i y_i = 0
\end{align}
\]
Because the dual problem is a lower bound of the primal problem, we need to maximize the equation above: \[
\begin{equation}
\max_{\boldsymbol{\sigma}}\min_{\boldsymbol{x}, b}L(\boldsymbol{x}, b, \boldsymbol{\sigma}) \sim \min_{\boldsymbol{w}}f(\boldsymbol{x})
\end{equation}
\]
By substituting the formulas that we got while solving the KKT conditions in \(L\) we get the final dual form: \[
\begin{align}
&\max_{\boldsymbol{\sigma}} \: \sum_{i=1}^{N}\sigma_i - \frac{1}{2} \sum_{i=1}^{N}\sum_{j=1}^{N} \sigma_i \sigma_j y_i y_j \phi(\boldsymbol{x}_i)^\top \phi(\boldsymbol{x}_j) \\
&\text{s.t.} \quad \sigma_i \geq 0 \\
&\text{s.t.} \quad \sum_{i=1}^{N}\sigma_iy_i = 0 \\
&\forall i \in \{1, \dots, N\}
\end{align}
\]
Then, we transform the optimization problem into a minimization and introducting the Gram matrix \(\boldsymbol{K}_{ij} = \phi(\boldsymbol{x}_i)^\top \phi(\boldsymbol{x}_j)\): \[
\begin{align}
&\min_{\boldsymbol{\sigma}; \boldsymbol{\sigma} \geq 0} \frac{1}{2} \sum_{i=1}^{N}\sum_{j=1}^{N} \sigma_i \sigma_j y_i y_j \boldsymbol{K}_{ij} - \sum_{i=1}^{N}\sigma_i \\
&\text{s.t.} \quad \sigma_i \geq 0 \\
&\text{s.t.} \quad \sum_{i=1}^{N}\sigma_iy_i = 0 \\
&\forall i \in \{1, \dots, N\}
\end{align}
\]
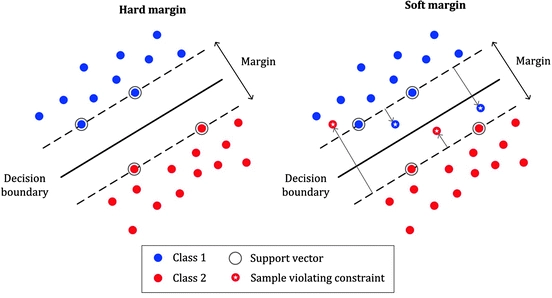
If the data is not linearly separable, even after using the kernel trick, we can use a soft margin classifier.
Soft Margin Classifier
Soft-margin classifiers introduce slack variables \(\zeta_i \geq 0\) as \(\zeta_i = |y_i - f_i|\) to allow the classifier to mis-classify some samples.
In fact, we allow the model to make mistakes to be able to separate non linearly separable data where:
\(\zeta_i = 0\) means that the point lies in the correct margin boundary.
\(0 < \zeta_i \leq 1\) the point lies inside the margin and on the correct side.
\(\zeta_i > 1\) the point lies in the incorrect boundary.
The primal optimization is then: \[\begin{align}
&\min_{\boldsymbol{w}, b}\frac{1}{2}||\boldsymbol{w}||^2 - C\sum_{i=1}^{N}\zeta_i\\
&\text{s.t} \quad y_i(\boldsymbol{w}^\top \boldsymbol{x}_i + b) \geq 1 - \zeta_i \\
&\text{s.t} \quad \zeta_i \geq 0 \\
&\forall i \in \{1, \dots, N\}
\end{align}\] where \(C\) is the regularization parameter that controls the number of errors we are willing to tolerate on the training set.
Then the dual problem for the soft margin model is: \[\begin{align}
&\max_{\boldsymbol{\sigma}}\sum_{i=1}^{N}\sigma_i - \frac{1}{2} \sum_{i=1}^{N}\sum_{j=1}^{N} \sigma_i \sigma_j y_i y_j \phi(\boldsymbol{x}_i)^\top \phi(\boldsymbol{x}_j) \\
&\text{s.t.} \quad 0 \leq \sigma_i \leq C \\
&\text{s.t.} \quad \sum_{i=1}^{N}\sigma_iy_i = 0 \\
&\forall i \in \{1, \dots, N\}\\
\end{align}\]
Implementation
We will compute the convex optimizations using the CVXOPT package. The solver performs the following optimization: \[\begin{align}
\min &\frac{1}{2} \boldsymbol{\sigma}^\top \boldsymbol{P} \boldsymbol{\sigma} - 1^\top\boldsymbol{\sigma} \\
&\text{s.t.} \\
&- \sigma_i \leq 0 \\
&\boldsymbol{y}^\top \boldsymbol{\sigma} = 0
\end{align}\]
As you have probably guess, we will have to convert the dual problem in matrix form, let’s define: \[\begin{align}
&P_{ij} = y_i y_j \boldsymbol{K}_{ij} \\
&\boldsymbol{w} = \sum_{i=1}^{N} y_i \sigma_i\phi(\boldsymbol{x}_i) \\
&b = y_s - \sum_{m \in S} \sigma_m y_m \phi(\boldsymbol{x}_m)^\top \phi(\boldsymbol{x}_s) \\
\end{align}\] where \(S\) is the set of support vectors such as \(\sigma_i > 0\). We can solve the hard margin optimization problem by solving: \[\begin{align}
\min &\frac{1}{2} \boldsymbol{x}^\top\boldsymbol{P}\boldsymbol{x} + \boldsymbol{q}^\top\boldsymbol{x}\\
&\text{s.t.} \\
&\boldsymbol{G}\boldsymbol{x} \leq h \\
&\boldsymbol{A}\boldsymbol{x} = 0
\end{align}\] where \(h\) is a column of ones, \(\boldsymbol{A}\) contains the labels and \(\boldsymbol{G}\) is a diagonal matrix full of \(-1\).
Here is the pseudo-algorithm for training an SVM:
Compute \(\boldsymbol{P}\).
Compute \(\boldsymbol{w}\).
Find the support vectors \(S\) by finding any data point where \(\sigma_i > 0\).
Compute \(b\).
To predict, compute: \[\begin{align}
y_{test} = \text{sign}\left(\boldsymbol{w}^\top \phi({\boldsymbol{x}_{test}}) + b \right)
\end{align}\]
In matrix form the dual optimization is: \[\begin{align}
\min &\frac{1}{2} \boldsymbol{\sigma}^\top \boldsymbol{P} \boldsymbol{\sigma} - 1^\top\boldsymbol{\sigma} \\
&\text{s.t.} \\
&- \sigma_i \leq 0 \\
&\boldsymbol{y}^\top \boldsymbol{\sigma} = 0
\end{align}\]
For training a soft margin classifier, we add a constraint on \(C\): \[\begin{align}
\min &\frac{1}{2} \boldsymbol{\sigma}^\top \boldsymbol{P} \boldsymbol{\sigma} - 1^\top\boldsymbol{\sigma} \\
&\text{s.t.} \\
&- \sigma_i \leq 0 \\
&\sigma_i \leq C \\
&\boldsymbol{y}^\top \boldsymbol{\sigma} = 0
\end{align}\]
def linear_kernel(X_1, X_2):"""Computes a dot product between two vectors"""return np.dot(X_1, X_2)
class SupportVectorClassifier():"""Class for both the hard margin and soft margin classifiers Attributes: kernel: A function for the kernel function to apply. C: If using soft margin, it is a float controling the tolerance to misclassification. sv_sigma: A torch tensor for the slack variables of the support vectors. sv: A torch tensor for the features of the support vectors. sv_y: A torch tensor for the labels of the support vectors. w: A torch tensor for the weights of the model, only used if the kernel is linear. b: A float for the bias. """def__init__(self, kernel, C=None):"""Init function of the SVC"""self.kernel = kernelself.C = Cdef fit(self, X, y):"""Trains the SVC model Args: X: A torch tensor for the data. y: A torch tensor for the labels. """# Building the cvxopt matricesiflen(y.shape) ==1: y = np.expand_dims(y, axis=1) y = y.astype(float) n_samples, n_features = X.shape K = np.zeros((n_samples, n_samples))for i inrange(n_samples):for j inrange(n_samples): K[i, j] =self.kernel(X[i, :], X[j, :]) q = cvxmat(np.ones((n_samples, 1)) *-1.) A = cvxmat(y.T) b = cvxmat(0.) P = cvxmat(np.outer(y, y) * K)ifself.C isNone: G = cvxmat(np.eye(n_samples) *-1.) h = cvxmat(np.zeros((n_samples, 1)))else: col_1 = np.eye(n_samples) *-1. col_2 = np.identity(n_samples) G = cvxmat(np.vstack((col_1, col_2))) col_1 = np.zeros(n_samples) col_2 = np.ones(n_samples) *self.C h = cvxmat(np.hstack((col_1, col_2)))# Compute the convex optimization sigma = np.array(solver.qp(P, q, G, h, A, b)['x'])# Gather support vectors sv_idx = sigma >1e-5self.sv_sigma = np.expand_dims(sigma[sv_idx], axis=1) sv_idx = np.squeeze(sv_idx)self.sv = X[sv_idx, :]self.sv_y = y[sv_idx]# If linear kernel, compute w, otherwise calculate it in pairwise# fashion once we predictifself.kernel == linear_kernel: w = np.sum(self.sv_y *self.sv_sigma *self.sv, axis=0)self.w = np.expand_dims(w, axis=1)else:self.w =None# Gather all pairwise distance of the support vectors idx = sv_idx.astype(int).nonzero()[0] b =0 sv_sigma_flat =self.sv_sigma.flatten() sv_y_flat =self.sv_y.flatten()for i inrange(len(idx)): b +=self.sv_y[i] b -= np.sum(sv_sigma_flat * sv_y_flat * K[idx[i], sv_idx]) b /=len(idx)self.b = bdef project(self, X):"""Projects the data into the SVC hyperspace"""ifself.w isnotNone:return np.dot(X, self.w) +self.belse: pred = np.zeros(X.shape[0])for i inrange(X.shape[0]): cur_pred =0for j inrange(self.sv_sigma.shape[0]): cur_pred +=self.sv_sigma[j] *self.sv_y[j] *self.kernel(X[i], self.sv[j]) pred[i] = cur_predreturn pred +self.bdef predict(self, X):"""Projects the data than return the sign of the prediction as label"""return np.sign(self.project(X))
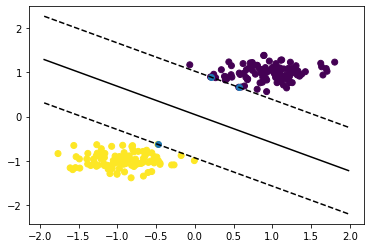
The soft margin classifier places the classification plane in the middle of the two cluster in the direction of highest variance. Well done !
Hard Margin Classifier with Kernel RBF
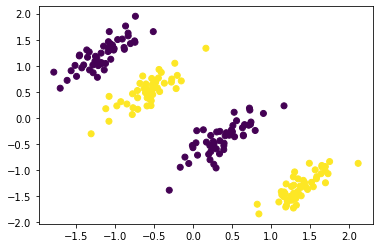
def generate_non_linear(mean_1, mean_2, mean_3, mean_4, cov):"""Generates non linear data from gaussian distributions Mean 1 to 4 is are the means that generate 4 clusters and cov is their covariance matrix. """ X_1 = np.random.multivariate_normal(mean_1, cov, 50) X_1 = np.vstack((X_1, np.random.multivariate_normal(mean_3, cov, 50))) y_1 = np.ones(len(X_1)) X_2 = np.random.multivariate_normal(mean_2, cov, 50) X_2 = np.vstack((X_2, np.random.multivariate_normal(mean_4, cov, 50))) y_2 = np.ones(len(X_2)) *-1 X = np.vstack([X_1, X_2]) y = np.hstack([y_1, y_2]) X = StandardScaler().fit_transform(X)return X, y
<matplotlib.collections.PathCollection at 0x16c4c9caf08>
Even the linear soft margin model cannot fit well this data. For solving this problem we will use the kernel radial basis function (RBF).
def polynomial_kernel(X_1, X_2, p):"""Computes the polynomial kernel where p is the degree of the polynomial"""return (1+ np.dot(X_1, X_2)) ** pdef kernel_rbf(X_1, X_2, sigma=1.0):"""Computes the kernel RBF where sigma is the bandwith"""return np.exp(-np.linalg.norm(X_1 - X_2) **2/ (2* sigma **2))
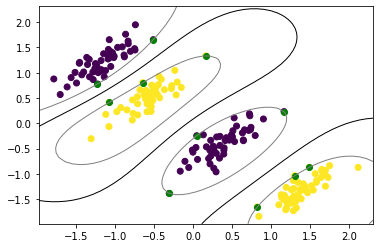
def plot_svc_rbf(X, y, svc):"""Plots the hyperplane and margins of a SVC with rbf kernel""" plt.scatter(X[:, 0], X[:, 1], c=y) sv = svc.sv plt.scatter(sv[:, 0], sv[:, 1], c='g') axis_min, axis_max = plt.gca().get_xlim() X1, X2 = np.meshgrid(np.linspace(axis_min, axis_max, 50), np.linspace(axis_min, axis_max,50)) X = np.array([[x1, x2] for x1, x2 inzip(np.ravel(X1), np.ravel(X2))]) Z = svc.project(X).reshape(X1.shape) plt.contour(X1, X2, Z, [0.0], colors='k', linewidths=1, origin='lower') plt.contour(X1, X2, Z +1, [0.0], colors='grey', linewidths=1, origin='lower') plt.contour(X1, X2, Z -1, [0.0], colors='grey', linewidths=1, origin='lower') plt.axis("tight") plt.show()
plot_svc_rbf(X, y, svc_rbf)
Conclusion
Support Vector Machines have a variety of kernels to fit the most complex data. SVMs work really well when there is a clear margin of separation between classes and are very effective on data with high dimensionality. Unfortunately, SVMs are not suited for large scale datasets due to their computational complexity. Furthermore, there is no probabilistic explanation of their prediction and they do not perform well on very noisy data.
Congratulations ! This article was the last of my Machine Learning series. Hope you enjoyed the journey !
Stay in touch
I hope you enjoyed this article as much as I enjoyed writing it!
Feel free to DM me any feedback on LinkedIn or email me directly. It will be highly appreciated.
That's what keeps me going!
Subscribe to get the latest articles from my blog delivered straight to your inbox!
About the author
Axel Mendoza
Senior MLOps Engineer
I'm a Senior MLOps Engineer with 6+ years of experience building production-ML systems.
I write long-form articles on MLOps to help you build too!