
I'm a Senior MLOps Engineer with 6+ years of experience building production-ML systems.
I write long-form articles on MLOps to help you build too!

Are you tired of keeping track of your machine learning experiments in scattered log files? This MLflow tutorial will solve all your problems! With this open-source platform, you can finally say goodbye to the days of lost logs and models.
It not only simplifies the management of your machine learning projects but also provides a unified interface for tracking your experiments, packaging your code, and deploying your models 😎
In this article, we will cover the fundamentals of MLflow, highlight its essential features, discuss its limitations, and, most importantly, explain why MLflow is crucial for collaborative machine learning projects 🚀
Before starting, if you’re interested in deploying MLflow on Google Cloud Platform, feel free to read my MLflow GCP deployment guide.
A GitHub Template for Machine Learning Projects
I’m excited to share that I have built a MLflow template on GitHub that you can use to create a new repository with all the necessary components for a streamlined machine learning workflow. This template includes the following awesome features:
- Sample Pytorch script that training on MNIST and logs metrics and parameters to MLflow
- Pre-built Continuous Integration (CI) with guidelines for customization
- Pre-commit configuration
- Advise on using the GitHub Flow workflow.
This template was built on top of my Python CI Template, feel free to read the related article to have a deeper understanding of its core features.
With this template, you can quickly set up a new machine learning project with all the necessary tools and configurations, saving you time and effort. Simply clone the template repository and customize it as you see fit. I will refer to this template throughout the article to show you how to use MLflow in practice.
MLflow Demystified

MLflow is an open-source platform for Machine Learning that covers the entire ML-model lifecycle, from development to production and retirement. It is a central place to collaborate and manage model lifecycle, providing data science teams with an efficient and organized workflow.
MLflow is composed of the following main modules:
- Tracking: it tracks experiments by logging parameters, metrics, and artifacts in a centralized location.
- Packaging: allows you to package your code and models in a reproducible way.
- User Interface: you can visualize your experiments and compare past runs with new ones.
- Model Registry: provides a central registry for storing and managing your models in a structured way, including versioning, staging, and deployment.
- Model Deployment: allows you to deploy your models in production.
Continue reading, as we will provide a detailed explanation of each module and the reasons why you should use them 🤓
Advantages of MLflow
In my opinion, the main advantages of MLflow are: 👍
- Compatibility: it is designed to work with a wide range of machine learning libraries, including TensorFlow, PyTorch, scikit-learn and more
- Flexibility: You can use MLflow with a variety of deployment options, including on-premise, cloud, and hybrid environments as well as integrating in other tools such as Kubeflow
- A large community of users and contributors
- Easy to use
MLflow is the most widely used framework in the ML community, particularly in the category of experiment tracking tools. It is used by companies such as Databricks, Facebook, Booking.com and many more. This is a very important aspect when deciding to learn a new framework as it can be cumbersome to spend time learning a tool that will fall out of favor in the future 😭
Overall, data science teams can streamline their workflow, increase productivity, and reduce the time and effort required to develop machine learning models.
MLflow Drawbacks
MLflow is a great tool, but it is not perfect. After using MLflow on several projects, I have identified two main issues:
- Deployment: The deploying features are very limited and are suitable for small projects only. If you want to deploy your models in production with medium to high availability, you will need to use other tools such as BentoML or Nvidia Triton.
- Pipeline Orchestration: MLflow only supports linear pipelines and does not allow the building of Directed Acyclic Graphs (DAGs) workflows. This means that you cannot have a pipeline of models that are executed in parallel. This is a big drawback for data science teams that want to build complex pipelines. Fortunately, MLflow can be used in conjunction with other complementary tools. The tracking and repoducibility features are very useful in my opinion and it is a huge step up to use MLflow collaboratively against not using any tool.
MLflow Basics

In this section, we will go through the most important features from the MLflow documentation. We will go through each of these features in detail and provide examples on:
- using the Tracking API with PyTorch to log metrics and artifacts
- packaging code as an MLflow Project for reproducibility
- logging an MLflow Model for versioning and sharing
- setting up a Tracking Server with a Postgres backend for collaboration with your team
- leveraging the MLflow Model Registry for model deployment and governance
By the end of this article, you will have a solid understanding of how to use MLflow to streamline your machine learning workflow and collaborate effectively with your team 🤝. So Stay tuned !
Installation
First, install the virtualenvwrapper package:
sudo apt-get install python3.10 python3.10-venv python3-venv
sudo apt-get install python3-virtualenv
pip install virtualenvwrapper
python3.11 -m pip install virtualenvwrapper
echo "export WORKON_HOME=$HOME/.virtualenvs
export PROJECT_HOME=$HOME/Devel
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
source ~/.local/bin/virtualenvwrapper.sh" >> ~/.bashrcNext, create a new Python environment:
mkvirtualenv myenv -p python3.10Install the dependencies:
python -m pip install --upgrade pip
pip install -r requirements.txtUpload Experiment’s Logs
Follow along by cloning the MLflow template repository here.
MLflow Quickstart
In the mymodule/mlflow_quickstart.py file, you can find a simple example of using the MLflow Tracking API. Here are the MLflow functions to log parameters, metrics and artifacts:
from mlflow import log_metric, log_param, log_artifacts
# Log a paramater(like batch_size, epochs, learning_rate, etc.)
log_param("param_name", parameter)
# Log a metric (like accuracy, loss, etc.)
log_metric("metric_name", metric)
# Log an artifact (like a trained model or a visualization)
log_artifact("path/to/artifact")MLflow with PyTorch
In the mymodule/mnist_pytorch_training.py file, you can find how to upload logs to MLflow inside a PyTorch loop.
Add a simple line to log the train_loss.
import mlflow
nb_batches = int(size / dataloader.batch_size)
for batch, (input_data, ground_truth) in enumerate(dataloader):
input_data = input_data.to(device)
ground_truth = ground_truth.to(device)
pred = model(input_data)
loss = loss_fn(pred, ground_truth)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss = loss.item()
# Add this line to log the train_loss
mlflow.log_metric('train_loss', loss, step=batch)In the next section, we will see how to visualize the results in the MLflow UI. Run python train.py to train an MNIST model and upload the logs to the MLflow server.
MLflow User Interface (UI)
Starting the MLflow UI is as simple as:
mlflow uiThis command starts a MLflow Tracking Server on your local machine. You can then access the UI at http://localhost:5000.
As you can see in the screenshot below, the UI is very intuitive and easy to use:
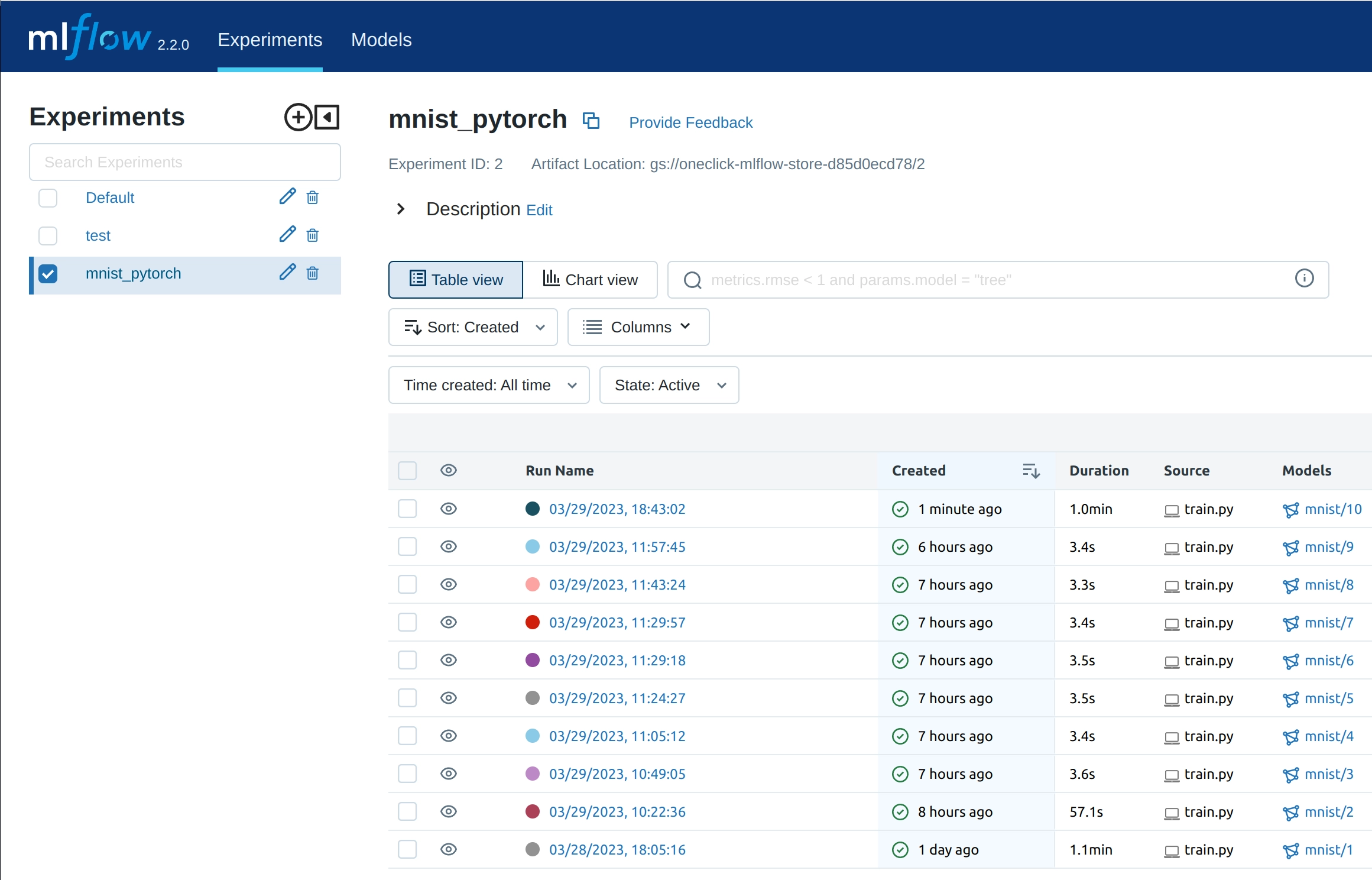
At the top left corner, you can see the name of the experiment. In the center of the page, you can find a listing of all the experiments that you have run. Feel free to click on one to explore the logs.
MLflow Project: Reproducibility Is All You Need

MLflow Project is an awesome module that helps you share your whole machine learning project with others without any headache. You can bundle up your code, dependencies, and parameters in a YAML file and create a source distribution or Docker container that others can easily run on their computer.
It’s super handy because MLflow runs your project in a safe and isolated environment (Conda, Pip, or Docker) so everyone uses the same environment. This makes it simple to track and reproduce the exact settings and parameters that were used to run the project, and the results and outputs generated by the code. It’s great for comparing different versions of your model or experiment, and reproducing the results on different computers.
Packaging your Project
First, let’s install pyenv:
curl -L https://github.com/pyenv/pyenv-installer/raw/master/bin/pyenv-installer | bashPackage your project with a MLproject file:
name: MLflow Template
python_env: environment.yaml
entry_points:
main:
parameters:
epochs: {type: int, default: 1}
batch_size: {type: int, default: 64}
train_on_first_n: {type: int, default: 0}
command: "python train.py --epochs {epochs} --batch_size {batch_size} --train_on_first_n {train_on_first_n}"As you can see, we can pass parameters to the train.py script that matches the argparse arguments defined in the file.
We will use a environment.yaml file to specify the virtualenv dependencies:
python: "3.10"
# Dependencies required to build packages. This field is optional.
build_dependencies:
- pip
- setuptools
- wheel==0.37.1
dependencies:
- mlflow
- pytorch
...Running MLflow Project
To run an MLflow Project, you need to specify the URI of the project. The URI can be a local path. For example, to run the project in the current directory, you can run:
mlflow run . --experiment-name <your-experiment-name>You can pass command line arguments this way:
mlflow run . --experiment-name <your-experiment-name> -P epochs=10 -P batch_size=128 -P train_on_first_n=1048Now prepare to have your mind blown 🤯. You can also run the project from a GitHub repository URI:
mlflow run git@github.com:ConsciousML/mlflow-template.git \
--experiment-name <your-experiment-name> \
-P epochs=10 \
-P batch_size=128 \
-P train_on_first_n=1048That’s right ! You can run a project from a GitHub repository URL without even having to clone or create the project environment. This opens up a whole new world of possibilities for reproducibility and collaboration.
Imagine you are working on a project with a team of data scientists. You can now share your project URL with your team members and they can run it ! They can simply change the input data and parameters and it will work out of the box. Plus, they can share the result of the experiment with you using the MLflow UI 😍
MLflow Models

The MLflow Models module is also an awesome addition to the framework. With this handy tool, you can easily track your model’s weights and architecture by logging them onto the MLflow Server 📈 It’s a great way to keep your machine learning models in check !
Saving a Model
Logging a PyTorch model can be done quite easily. By including a requirements.txt file that lists the necessary dependencies, the MLflow server can automatically install them when the model is loaded
mlflow.pytorch.log_model(
model,
"model",
pip_requirements=['torch', '-r requirements.txt'],
registered_model_name='mnist'
)Loading a Model
For loading a model, go to the Run tab in the MLflow UI, and locate the run_id. You can find the run_id in the image below:
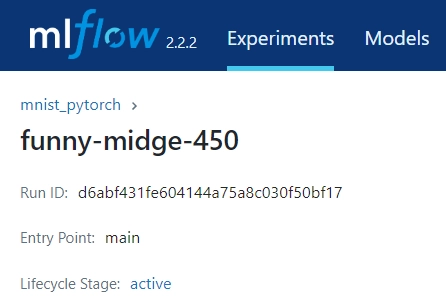
Now, you can effortlessly load the model using:
mlflow.pytorch.load_model(f"runs:/{run_id}/model")You can also load the model from its name and version. If you used the registered_model_name argument when logging the model, go to the MLflow UI, go to the Models tab and copy the name and version as in the image below:
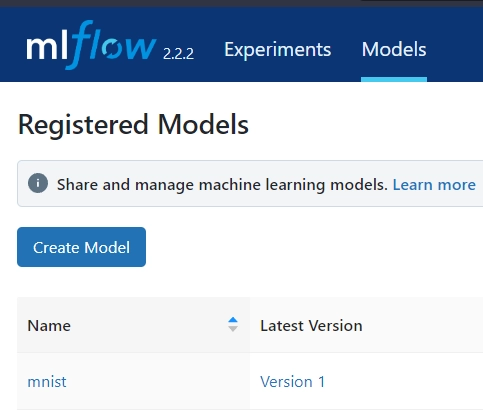
Then, you can load the model with the name and version:
mlflow.pytorch.load_model(f"models:/{name}/{version}")Stay tuned 👀, as we will delve deeper into the MLflow Model Registry in the next section.
Tracking Server With Postgres Backend
Before being able to use the MLflow Model Registry, you need to run a MLflow tracking server with a database backend.
Here is how to do it in 8 simple steps 🔢
- Install postgresql:
sudo apt-get install postgresql postgresql-contrib postgresql-server-dev-all- Run psql with the default postgres user:
sudo -u postgres psql- Create a database and user:
CREATE DATABASE mlflow;
CREATE USER mlflow WITH ENCRYPTED PASSWORD 'mlflow';
GRANT ALL PRIVILEGES ON DATABASE mlflow TO mlflow;- Install psycopg2 library to connect to Postgres from Python:
sudo apt install gcc
pip install psycopg2- Create a
mlrunsdirectory to store the MLflow tracking data:
mkdir ~/mlruns- Run local MLflow tracking server with Postgres backend:
mlflow server --backend-store-uri postgresql://mlflow:mlflow@localhost/mlflow --default-artifact-root file:/home/boxy/mlruns -h 127.0.0.1 -p 5000- Add the following lines to
~/.bashrcto set the MLflow tracking URI:
echo "export MLFLOW_TRACKING_URI=http://127.0.0.1:5000" >> ~/.bashrc- Run the following command to run the MLflow project:
mlflow run . --experiment-name mnist_pytorchOpen your Mlflow tracking server in your browser and you should see the run logged in the Runs tab.
Congrats!🎉 You now have MLflow running on a database backend! Next up, let’s explore the wonders of the MLflow Model Registry.
Model Registry: Tags & Versions

The MLflow Model Registry is a powerful tool that enables you to manage and organize your models by registering and versioning them. Registering a model involves creating a permanent record of a trained machine learning model in a central repository.
You can use the Model Registry to:
- Register models
- Transition models through stages of development and deployment
- Manage model versions
- Assign model versions to stages
- Query models and model versions
- Manage model lineage
Registering a Model
There is multiple ways to register a model:
- From the MLflow UI (see this link)
- From the MLflow API
In this example, we are using the MLflow API to register a model:
mlflow.pytorch.log_model(
model,
"model",
pip_requirements=['torch', '-r requirements.txt'],
registered_model_name='mnist'
)As you can see, the registered_model_name argument is used to tag the model with a name. Each time we log a model with the same registered_model_name, a new version of the model is created.
Model Stages
In MLflow, Model Stages are different versions of a registered model that have been transitioned from one stage to another, such as from Staging to Production. Stages allow you to organize your different models and keep track of their evolution.
A model can be in one of the following stages:
None: The model is not registered in the registry.Staging: The model is being tested.Production: The model is in production.Archived: The model is archived.
You can change the stage of a model from the UI following this link or using the MLflow API as follows:
client = MlflowClient()
client.transition_model_version_stage(
name="mnist", version=1, stage="Production"
)Fetching a Model
Now this is the most exciting part! You can fetch a model from the registry using the MLflow API. In a production environment, you will load the Production version of the model. You do not have to worry to change the code or weights path. As soon as you change the stage of the model, MLflow will automatically load the new version of the model.
Here’s how to fetch a model from the registry with a model version:
model_name = "mnist"
model_version = 1
model = mlflow.pytorch.load_model(model_uri=f"models:/{model_name}/{model_version}")We can also fetch a model from the registry with a model stage:
model_name = "mnist"
model_stage = "Production"
model = mlflow.pytorch.load_model(model_uri=f"models:/{model_name}/{model_stage}")Conclusion
Congrats ! 🎉
You’ve learned the basics of MLflow and how to use it to track your machine learning experiments and models. Whether you’re a data scientist, machine learning engineer, or researcher, MLflow can help you streamline your workflow, collaborate with your team, and gain valuable insights from your experiments. So why not give it a try and take your machine learning projects to the next level ?
But wait, there’s more ! 🤩 You might be wondering how to collaborate with your team if MLflow is running on your local machine. No worries, I’ve got you covered 👍 In the next article, we’ll explore how to deploy MLflow on the Google Cloud Platform with Terraform and make it accessible to your entire organization.