
I'm a Senior MLOps Engineer with 6+ years of experience building production-ML systems.
I write long-form articles on MLOps to help you build too!

For a machine learning product to thrive in the long run, automating the acquisition of training data is paramount. This automation is a game-changer 🎮 for model builders, allowing them to sidestep the challenges of data extraction and cleaning. With this burden lifted, they can channel their energies into refining and optimizing their models, knowing the data they receive is of the highest quality 💎
This article aims at explaining the intricacies of constructing a modern data pipeline on the Google Cloud Platform (GCP). This content has been tailored for professionals in the AI field, thus providing meaningful details about my journey on building a data pipeline for ML data acquisition.
The pipeline we’re exploring focuses on handling low to mid-range data volumes. I’ve chosen a batch processing methodology, which means that the data is processed in batches rather than in real-time. To be more specific, Dagster orchestrates Airbyte and DBT to extract and transform data from Cloud SQL to BigQuery. This strategy has benn chosen because model builders often just need to refresh the warehouse periodically.
This article will cover the essential tools, steps and infrastructure choice, we made in designing the pipeline as well as highlighting both the advantages and drawbacks of the approach.
However, this article is not meant to provide code to build such a pipeline as its complexity greatly outstands the scope of an article. Instead, the focus will be on understanding the role of each tool and how they integrate together.
I hope this article will provide the insights to help you choose the right architecture for your data pipeline 🛠️
Before starting, if you need more information on Data Engineering fundamentals, feel free to read this article.
Data Pipeline Preliminaries

In this section, we will dive into the preliminary knowledge required to understand the context of the data pipeline.
What is ETL ?
ETL, an acronym for Extract, Transform, Load, is a foundational process in data engineering. It involves extracting data from various sources, transforming it into a usable format, and then loading it into a data warehouse. This process ensures that data is organized, consistent, and ready for analysis or other operations.
In this pipeline, we’ll be adopting the ELT approach, leveraging tools like Dagster, Airbyte, and DBT. Unlike the traditional ETL, where transformation happens before loading, ELT prioritizes loading data into the warehouse first and then transforming it. This shift in paradigm offers the following benefits:
- Flexibility: The ELT method allows for more adaptable and dynamic data transformations within the warehouse. This enabled the emergence of tools such as DBT.
- Easier Debugging: With source data readily available in the data warehouse, troubleshooting becomes more straightforward.
- Cost-Efficiency: While ELT does involve duplicating data, the associated costs are minimal, especially given the competitive pricing structures of modern data warehouses.
Why is ELT Crucial for an ML Team?
As a machine learning engineer, I’ve witnessed the recurrent challenges in machine learning teams. To gather up-to-date data, model builders often have to repeatedly navigate the cumbersome steps of data collection and preprocessing. Now let’s compare the following scenarios to illustrate the advantages of a standardized ELT process.
Scenario Without ELT
- Fragmented Data Sources: Without a structured ELT process, data scientists often grapple with data scattered across disparate sources. This means spending inordinate amounts of time just locating and accessing the right datasets.
- Manual Data Cleaning: Once data is located, data scientists need to manually clean and preprocess it. This is not just time-consuming but also error-prone, potentially leading to subpar models.
- Inconsistencies and Redundancies: In the absence of a systematic transformation process, the data could have inconsistencies and redundancies, which can adversely affect the training and efficiency of ML models.
- Delayed Model Training: With extended data preparation phases, the actual model development and training get delayed, leading to slower project turnarounds.
Scenario With ELT
- Centralized Data: ELT processes consolidate data from multiple sources, ensuring that ML teams have a centralized repository to tap into. This eliminates the time-consuming chase for data.
- Automated Data Preparation: ELT automates the cleaning and preprocessing stages, ensuring that the data is ML-ready. This not only saves time but also enhances accuracy, as human-induced errors are minimized.
- Uniform Data Structure: The transformation phase of ELT ensures that data conforms to a consistent structure, making it easier for ML algorithms to digest and learn from.
- Swift Model Iteration: With data readily available in the desired format, ML teams can swiftly move through the model building and iteration phases, accelerating innovation and deployment.
Conclusion
The effectiveness of ML models is deeply tied to the quality of the underlying data. Integrating ELT processes enables ML teams to address challenges in data acquisition and transformation more efficiently. With ELT in place, teams can dedicate more time and energy to their primary tasks: developing and fine-tuning their models.
Interacting with the Data Pipeline
The interaction with the data pipeline consists of three straight forward steps:
- Triggering: Users initiate the data flow through a user-friendly web interface. This interface serves as the gateway to execute various pipeline processes.
- Monitoring: It’s essential to have visibility into the pipeline’s progress. By accessing dedicated logs and monitoring tools, users can gain insights into each stage, ensuring smooth execution and early detection of any potential issues.
- Data Retrieval: Once the pipeline completes its processes, model builders can extract the refined data from the data warehouse and use it to train AI models.
Behind the Scenes

Diving deeper in the technical part of this article, this section will explore the tools, processes and infrastructure of the data pipeline.
Overview of the Tools
Terraform
Terraform, a widely used Infrastructure as Code (IaC) tool, enables engineers to interact with the infrastructure using code. It ensures repeatability and consistency in provisioning and managing cloud resources.
For building and maintaining complex infrastructure, IaC tools are almost mandatory. We chose terraform as our Iac tool as it supports all the tools in the modern stack that we deciced to implement. Moreover, it comes praticularly handy to integrate multiple tools together.
As demonstrated in one of my previous article on deploying MLflow on GCP, Terraform is a reliable tool that we can count on.
Google Cloud SQL
Cloud SQL is a managed relational database service designed for both scalability and adaptability. Within our pipeline, it provides a storage solution for the backend of Airbyte and Dagster as well as a temporary location to load databases from MySQL dump files.
BigQuery
BigQuery is a serverless, data warehouse tailored for scalability, and cost-efficiency. With its capacity to handle massive volumes of data without requiring manual server management, BigQuery empowers teams to store and analyse large datasets.
In our data pipeline, we use BigQuery as the destination of the ELT. Model builders will interact with it to retrieve up-to-date ML-ready data.
Dagster
Dagster is a modern data orchestrator designed to define, schedule, and monitor data workflows, ensuring that they flow seamlessly from one stage to the next. At its core, Dagster operates with two primary paradigms: task-based and asset-based workflows.
In the task-based approach, workflows are primarily constructed around discrete units of work, where each task carries out a specific function. Contrastingly, the asset-based perspective revolves around the data assets (database tables, files in storage buckets, …) produced and consumed within the workflow. It emphasizes lineage and the lifecycle of data, offering clarity on how data transforms and evolves through the system.
For our data pipeline, Dagster orchestrates Airbyte and DBT to extract and transform data from a MySQL, Cloud SQL instance, to our data warehouse: BigQuery.
Cloud Functions
Cloud Function is a serverless compute service offered by Google Cloud, enabling developers to execute code in response to specific events without the need to provision or manage servers. It’s designed to be lightweight, scalable, and highly responsive, making it ideal for event-driven applications and tasks.
In our data pipeline, a Cloud Function instance detects new MySQL dump files in GCS - which are replicas of our production database - and imports these dumps into a Cloud SQL instance to be available in the GCP ecosystem.
Airbyte
Airbyte is an open-source data integration platform, designed to provide users with the capability to replicate data from various sources into their data destinations of choice. It comes with a library of connectors for popular databases and platforms, allowing for the seamless movement of data across different ecosystems. Given its extensibility and flexibility, Airbyte has become a go-to solution for many when it comes to data synchronization tasks.
In the context of our data pipeline, Airbyte synchronizes the replicas of our production database in Cloud SQL to BigQuery, our data-warehouse.
Data Build Tool (DBT)
DBT, short for Data Build Tool, is a popular open-source software that facilitates the transformation of data within the data warehouse. It allows data teams to define, document, and execute data transformation workflows. With DBT, users can apply business logic and perform complex transformations using SQL, while also maintaining modularity and version control for their workflows.
In our pipeline, DBT plays a pivotal role when it comes to the post-ingestion phase of our data. Once the production data finds its way into BigQuery via Airbyte, DBT is called into action. Utilizing its robust transformation capabilities, we employ DBT to clean, pre-process, and structure the training data within BigQuery.
Steps of Data Pipeline
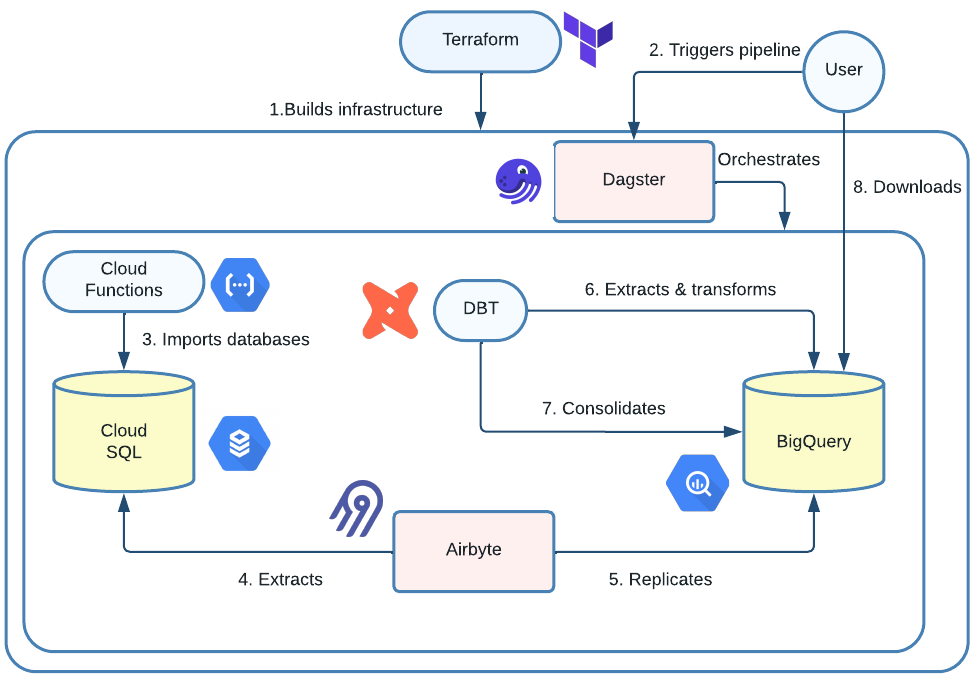
In this section, the data pipeline will be separated into 8 simple steps. Feel free to explore the flowchart above for an illustrated explanation of the following steps:
- Infrastructure Setup: With Terraform, the required cloud infrastructure is deployed accordingly in a reproducible fashion.
- User Triggers the Pipeline: Via Dagster’s web interface, the user manually initiates the pipeline run.
- Data Import: A Cloud Function is tasked to find the latest dump files in GCS and import the production databases into the Cloud SQL environment.
- Sensor Activation: Upon completion of the data import, Dagster’s sensor mechanism identifies the completion signal, getting ready for the subsequent steps
- Data Extraction: Airbyte extracts the relevant tables and columns from the databases in Cloud SQL.
- Data Replication: Airbyte replicates the data from step 4. to BigQuery.
- Data Transformation: With the raw data now residing in BigQuery, DBT performs the data cleaning and pre-processing.
- Data Consolidation: As we have multiple production databases, DBT aggregates their respective transformations in a single BigQuery dataset.
- Data Retrieval: The model builders can now download the ML-ready dataset from BigQuery.
The steps outlined provide a clear and structured roadmap for the entire data pipeline, ensuring efficient and streamlined ML operations. By adhering to this process, teams can seamlessly transition from raw data acquisition to deploying machine-ready datasets, while maintaining data integrity and consistency.
Data Pipeline Infrastructure
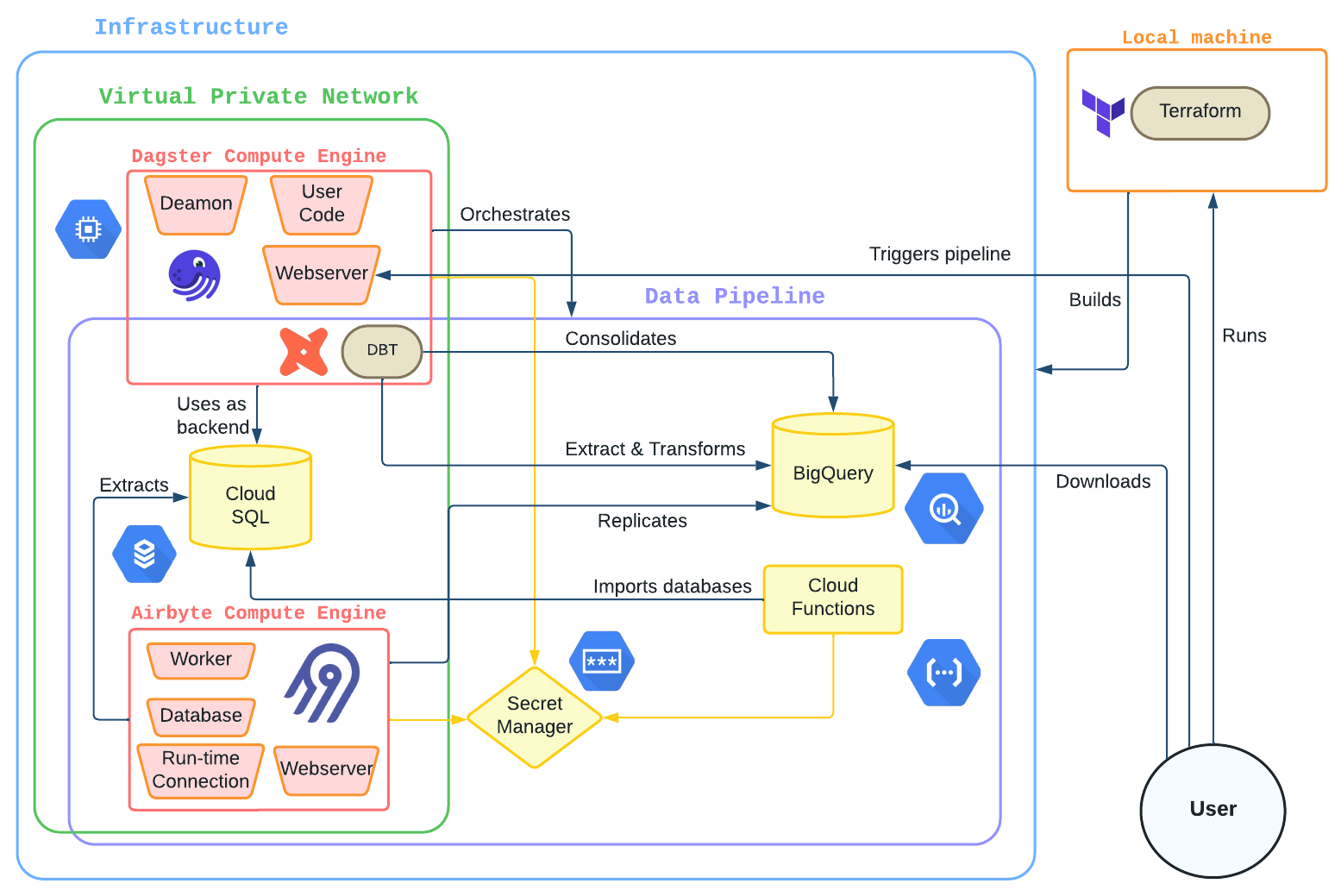
In this section, we’ll uncover the foundational elements that constitute the data pipeline’s infrastructure. Feel free to refer to the flowchart above for an illustration of the infrastructure supporting the ELT.
Service Deployment
For our pipeline to effectively operate and manage data flows, two pivotal services, Dagster and Airbyte, need to be actively deployed and monitored.
Dagster Deployment
As our primary orchestrator, Dagster is deployed on a e2-medium Compute Engine instance. In fact, as Dagster only performs the transformation with DBT, a medium instance is sufficient due to the fact that Airbyte does the heavy lifting.
Dagster is deployed to the instance with a Docker Compose configuration. As Dagster requires sensitive information to have read and write access to Cloud SQL and BigQuery, as well as a control permissions over Airbyte, we provide the necessary secrets from Google Secret Manager to a custom start-up script that executes right after the server is provisioned.
The DBT operations within Dagster have their own nuanced workflow. By utilizing a GitHub token in the startup script, the DBT repository gets cloned within the Dagster repository, functioning as a submodule. A key associated with the DBT service account is then embedded into this submodule, enabling Dagster to create manifests for each BigQuery dataset and execute the DBT code seamlessly.
Airbyte Deployment
Airbyte plays a central role in our data pipeline, handling the rigorous task of data replication. As such, its operational demands are more intensive than Dagster’s. To accommodate this, Airbyte is deployed on a more robust n1-standard-4 Compute Engine instance.
Similar to Dagster, the deployment process for Airbyte is streamlined using a startup script initiated upon the creation of the Compute Engine. It retrieves the required Docker Compose configurations, kickstarts the Airbyte services, and establishes the necessary environment.
A notable security measure in the setup process involves the Airbyte password that is needed by other services to interact with it. It’s securely uploaded to Google Secret Manager ensuring that access to the Airbyte platform is restricted.
There’s a built-in mechanism that ensures the Airbyte web server is accessible after it’s deployed. This mechanism diligently checks the server’s availability within a predetermined timeout duration, updating on the deployment’s progress. This verification is crucial as other parts of our infrastructure depend on this Airbyte instance, making API calls through Terrafrom to establish specific Airbyte resources such as sources, destinations, and connections.
Data Persistence
Ensuring the durability and accessibility of data is paramount in any pipeline, and in ours, a combination of Cloud SQL and BigQuery takes center stage:
- Cloud SQL: It acts as the backend for both Dagster and Airbyte. Its primary role is to safeguard the raw and intermediate data processed by these tools as well as their respective internal state. This ensures that even if Compute Engine instances are terminated or encounter issues, the data remains intact and unaffected.
- BigQuery: No matter the state of other infrastructure components, after each successful pipeline run, the resulting dataset is stored in BigQuery. This ensures that the processed data is not only retained but is also readily available for any subsequent analysis or operations.
In essence, our focus on data persistence guarantees that despite any potential issues in the infrastructure, data continuity and accessibility are always maintained.
Want to know more about this subject ? I’ve release an article especially for this purpose.
Virtual Private Cloud (VPC)
In today’s cloud-driven world, ensuring that resources remain secured while being interconnected is of utmost importance. Here’s where Virtual Private Clouds (VPC) come into play.
- What is a VPC? A VPC is a virtual network dedicated to your Google Cloud account. It provides a private space within the cloud, isolating your services and applications from the public internet. Within this space, resources can be provisioned, networked, and managed, all away from the prying eyes of the outside world.
- Deployment on VPC: In our architecture, the CloudSQL instance, Dagster’s and Airbyte’s Compute Engines are all deployed within a single VPC. This ensures that they are not only logically grouped but also can securely communicate amongst themselves.
- Private IP Connectivity: All these instances within our VPC communicate using private IP addresses. This private connectivity further enhances security by eliminating exposure to the public internet.
By leveraging VPCs, we’ve managed to create a network environment that is both functional and secure, safeguarding our data processing components from external threats.
Assessment & Challenges

Building a data infrastructure is no easy task. It comes with challenges and lessons at every turn. In this section, we’ll look back at what we faced, how we tackled each issue, and what we learned
Data Pipeline Advantages
As you might expect, we decided to build an ELT pipeline for data acquisition because the pros largely outweight the cons:
- Automation: Processes run smoothly and automatically, eliminating the need for manual operations.
- Reproducibility: Each execution of the pipeline yields consistent outcomes, ensuring reliability.
- Up-to-Date Data: The system ensures access to the most recent production data, facilitating the re-training process.
- Control: Model builds can request the up-to-date data themselves thus having direct influence over the data they use.
- Scalability: The infrastructure can be tweaked to accommodate the increasing data volume.
- Transparency: Every operation in the pipeline is logged, providing visibility and traceability.
Data Pipeline Drawbacks
While our data pipeline offers numerous advantages, it’s essential to recognize some inherent challenges and limitations:
- Complexity: Integrating various tools and systems can be a daunting task, requiring a deep understanding and expertise. As the infrastructure continues to grow, onboarding and training new machine learning engineers will become more intricate, adding layers to the complexity.
- Maintenance: The pipeline necessitates periodic updates and monitoring to ensure smooth operations. As the system integrates more tools, it demands knowledge spanning across every component, potentially increasing the maintenance overhead.
- Scalability Limitations: If the data needs grow to attain a massive volume, a tool such as Kubernetes, could be more suitable than a plain Docker Compose.
- Infrastructure Cost: Relying heavily on cloud platforms might result in significant financial commitments due to resource consumption over time. However, a potential advantage is that model builders can iterate faster on model trainings, leading to more efficient resource utilization and quicker time-to-value. This rapid iteration could translate into cost savings in the long run.
Real-World Challenges
In this section, we’ll review the practical challenges that emerged during the pipeline’s deployment and operation, offering insights into the complexities of implementing such a system in a live environment.
Dagster Workflow Integration
Dagster, as versatile as it is, exhibits certain nuances when integrating distinct workflow paradigms:
- Task-based Import: The process of importing databases using Cloud Function falls under the task-based model. This approach emphasizes executing individual tasks that can run in sequence or parallel, depending on dependencies.
- Asset-based ELT: The ELT component, on the other hand, adheres to an asset-based model. In this structure, the emphasis is on the data assets being produced, tracked, and consumed across tasks.
However, a notable limitation surfaces here: Dagster does not natively support direct dependency between these two paradigms. As a workaround, we leveraged the sensor feature. Sensors in Dagster are mechanisms that continuously monitor for certain conditions or events. By using sensors, we could detect the completion of the task-based database import and subsequently trigger the asset-based ELT, ensuring a seamless transition between the two stages.
Unstable Airbyte Compute Engine
During our work with Airbyte, we encountered several challenges. Given its beta status, it occasionally exhibited instability. When Airbyte crashed, pinpointing the root cause proved difficult.
This was primarily because the logs, which could provide insights into the issue, vanished when the associated Docker containers terminated.
A recurring theme of these interruptions was tied to computational resource constraints. Consequently, we dedicated time to meticulously monitor and adjust the system’s resource allocations, striving to strike a balance between system reliability and cost-effectiveness.
DBT Pipeline Duplication
In our pipeline, a unique challenge arose when dealing with DBT. There was a necessity to execute the same DBT code across different datasets. To differentiate between these datasets, we leveraged environment variables, which allowed DBT to target datasets.
However, integrating this strategy with Dagster proved to be more complicated than anticipated. The main stumbling block was Dagster’s handling of the configurations — the framework seemed to override environment variable each time a new DBT pipeline was loaded from the same code.
To fix this issue, we had to implement custom Dagster classes to modified this behavior. Unfortunately, this task was time consuming.
Reproducible Deployment
Ensuring a deployment process that can be consistently replicated without manual steps is a cornerstone for a robust data pipeline. This aspect not only ensures reliability but also boosts confidence when scaling or making adjustments.
However, we have technical problems when certain components depended on other infrastructure modules. Specifically, components like Airbyte connections required the prior deployment of other Terrfaform modules before they could function correctly. This presented a chicken-and-egg scenario, complicating the linear deployment process we initially envisioned.
Further compounding this challenge was the time-intensive nature of testing our reproducibility. Anytime a change was made to address these dependency issues, the entire infrastructure had to be reconstructed from the ground up to validate the new approach. This iterative process was not only laborious but also prolonged our deployment refinement phase.
Conclusion
In the vast and evolving field of machine learning, establishing a robust ELT pipeline is no longer a luxury but a necessity, particularly for growing ML teams. Such a pipeline not only streamlines operations but also ensures that teams are always working with the most recent and relevant data, enhancing the quality and efficiency of their development.
Building a modern data pipeline, while demanding, offers long-term rewards. By leaning on tools that are steadily gaining traction in the industry, we position ourselves to benefit from their growing feature sets and community support.
Lastly, while I’ve provided a summary based on our experiences, the world of data is diverse and ever-changing. I greatly encourage readers to use the insights provided by this article to craft a pipeline that best fits their unique requirements.
The journey might be challenging, but the rewards, in terms of efficiency and insights, are well worth the effort!