import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import plotly.graph_objects as go
import plotly.express as px


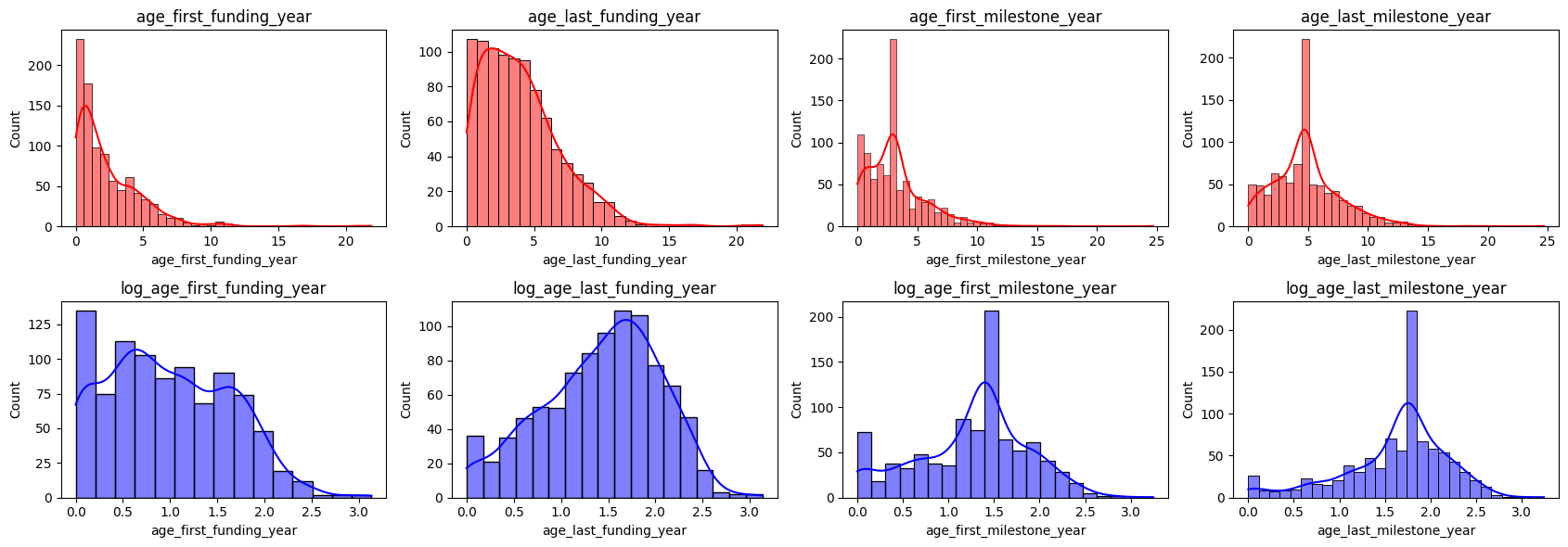
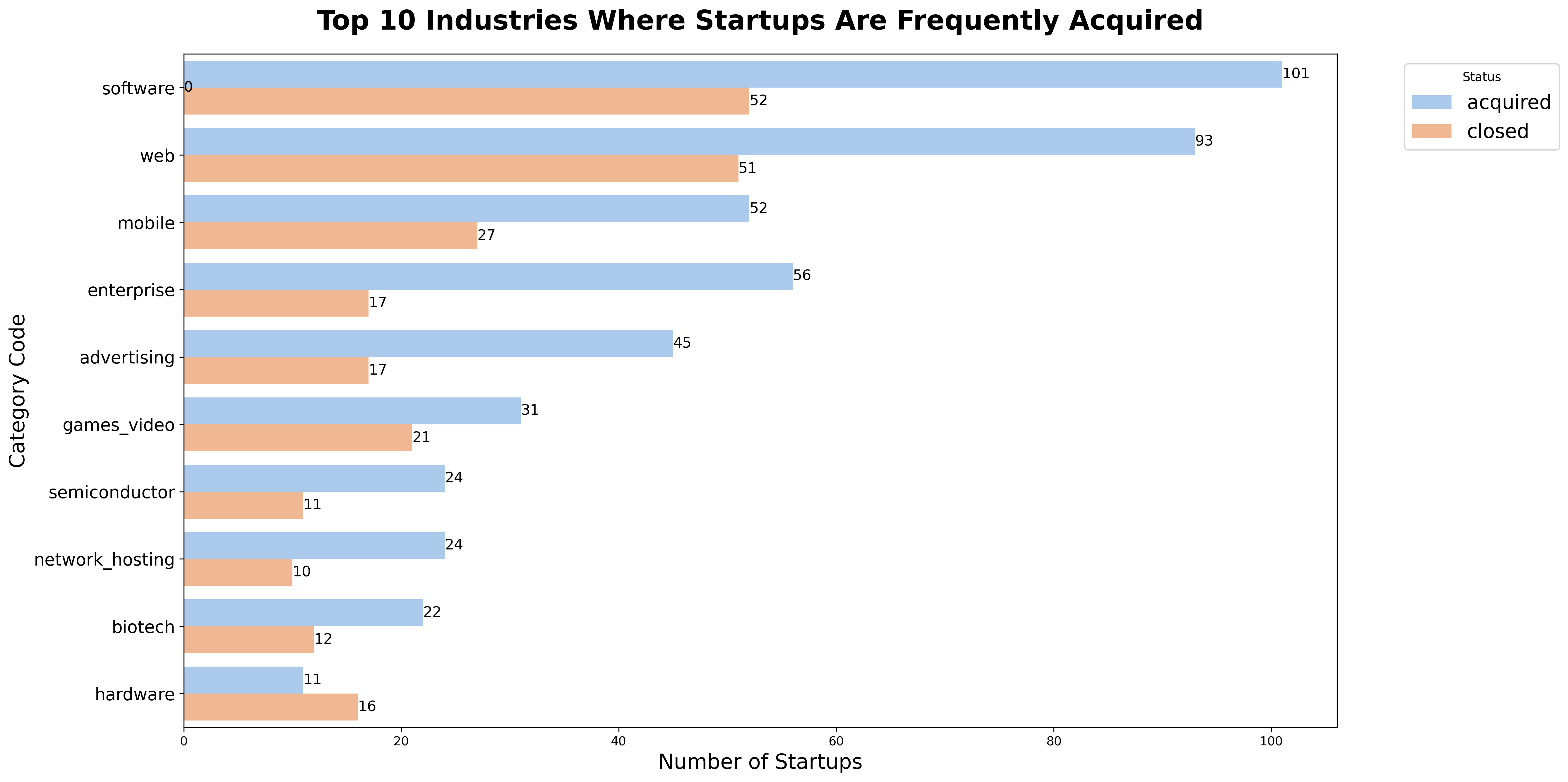
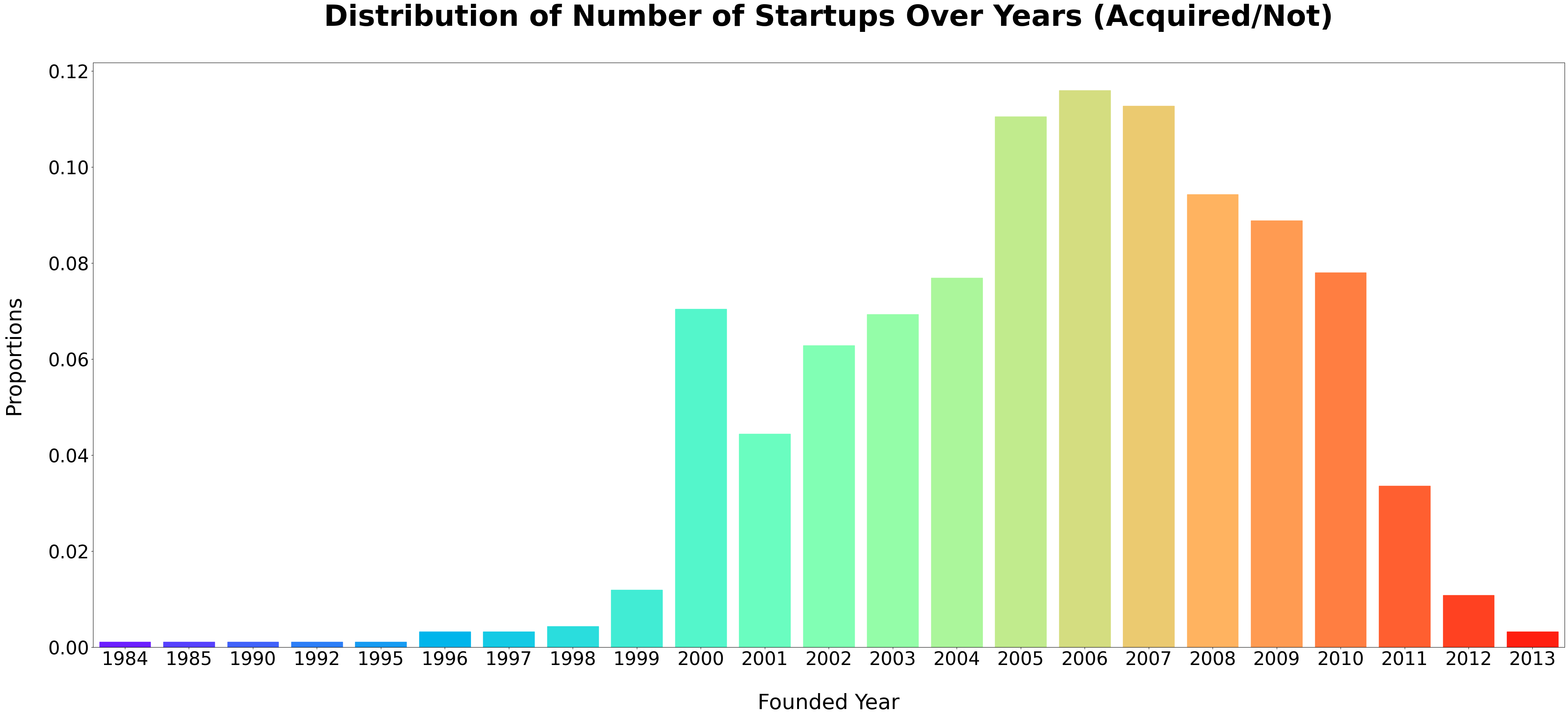
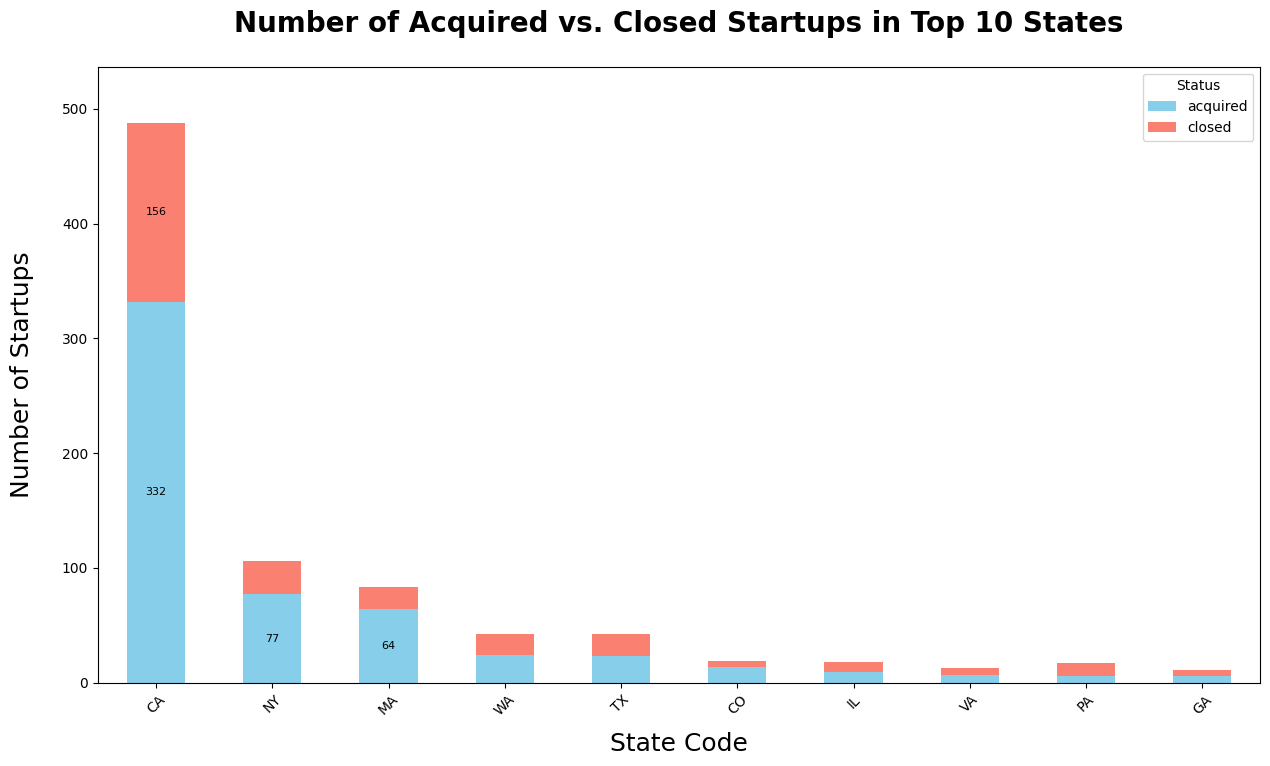
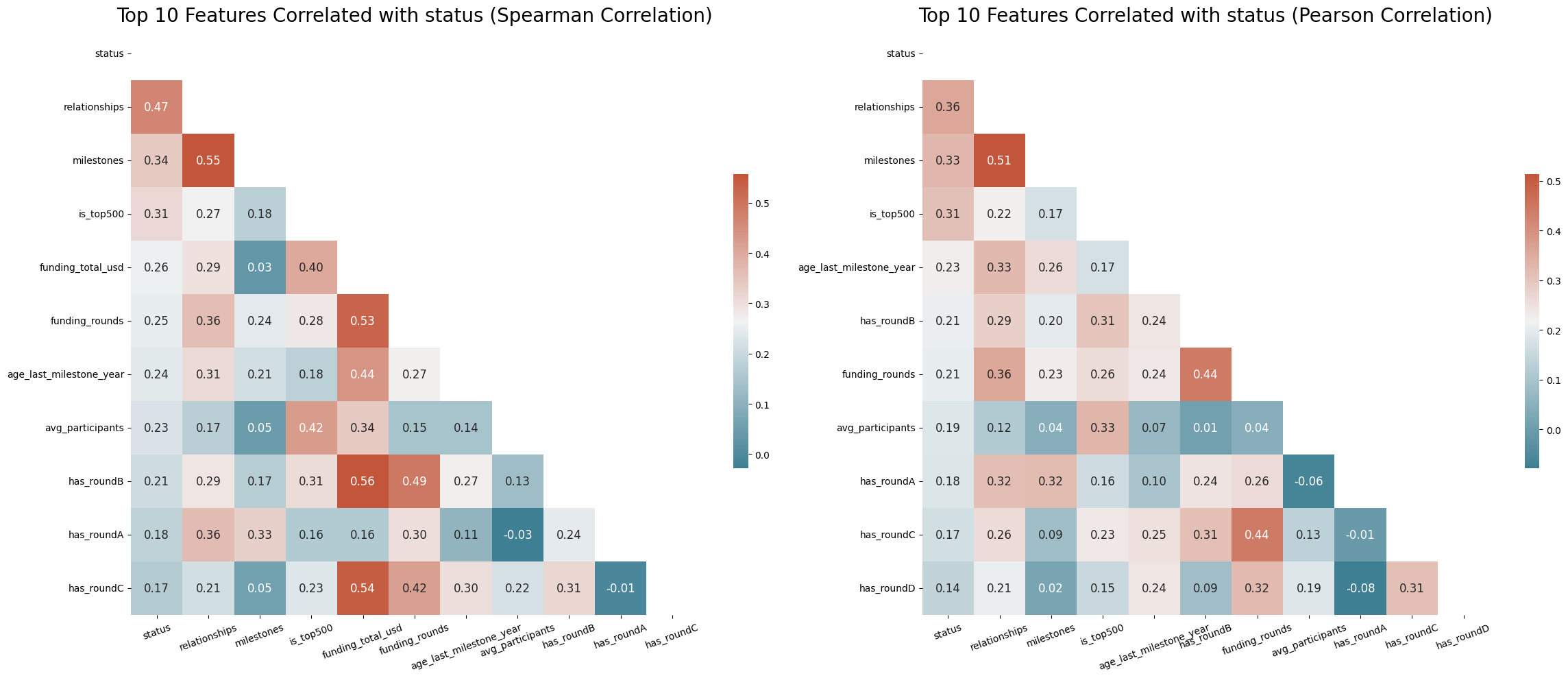
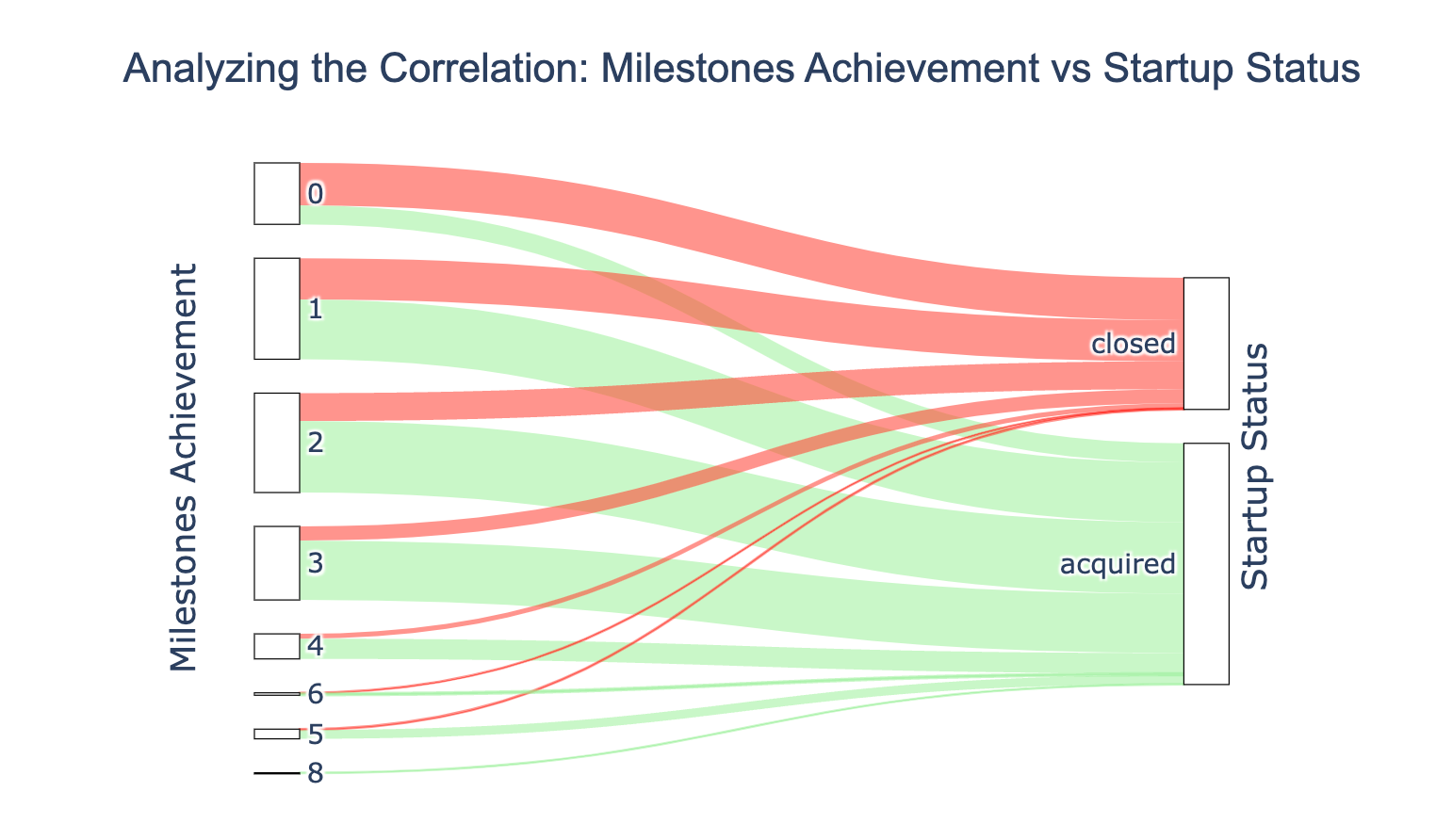
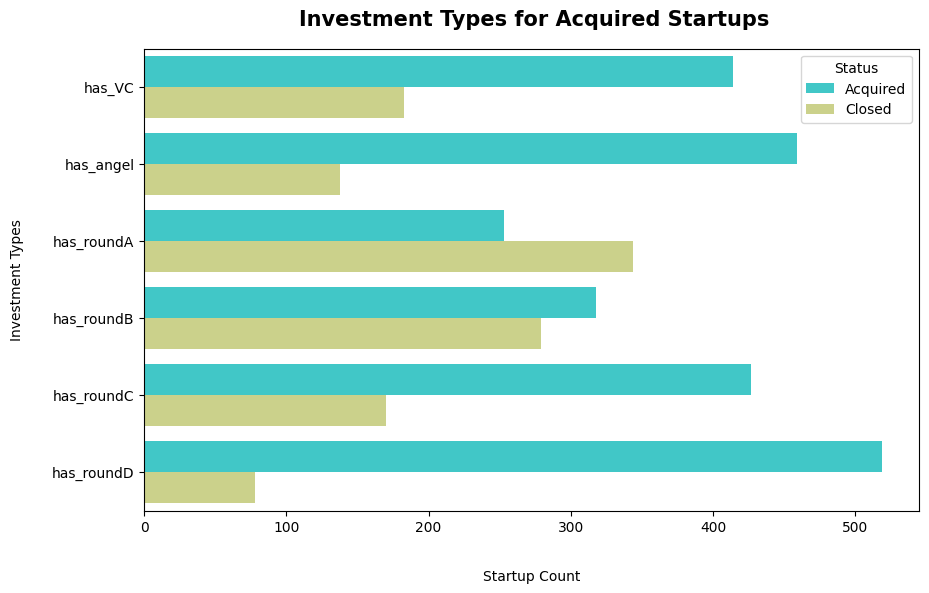
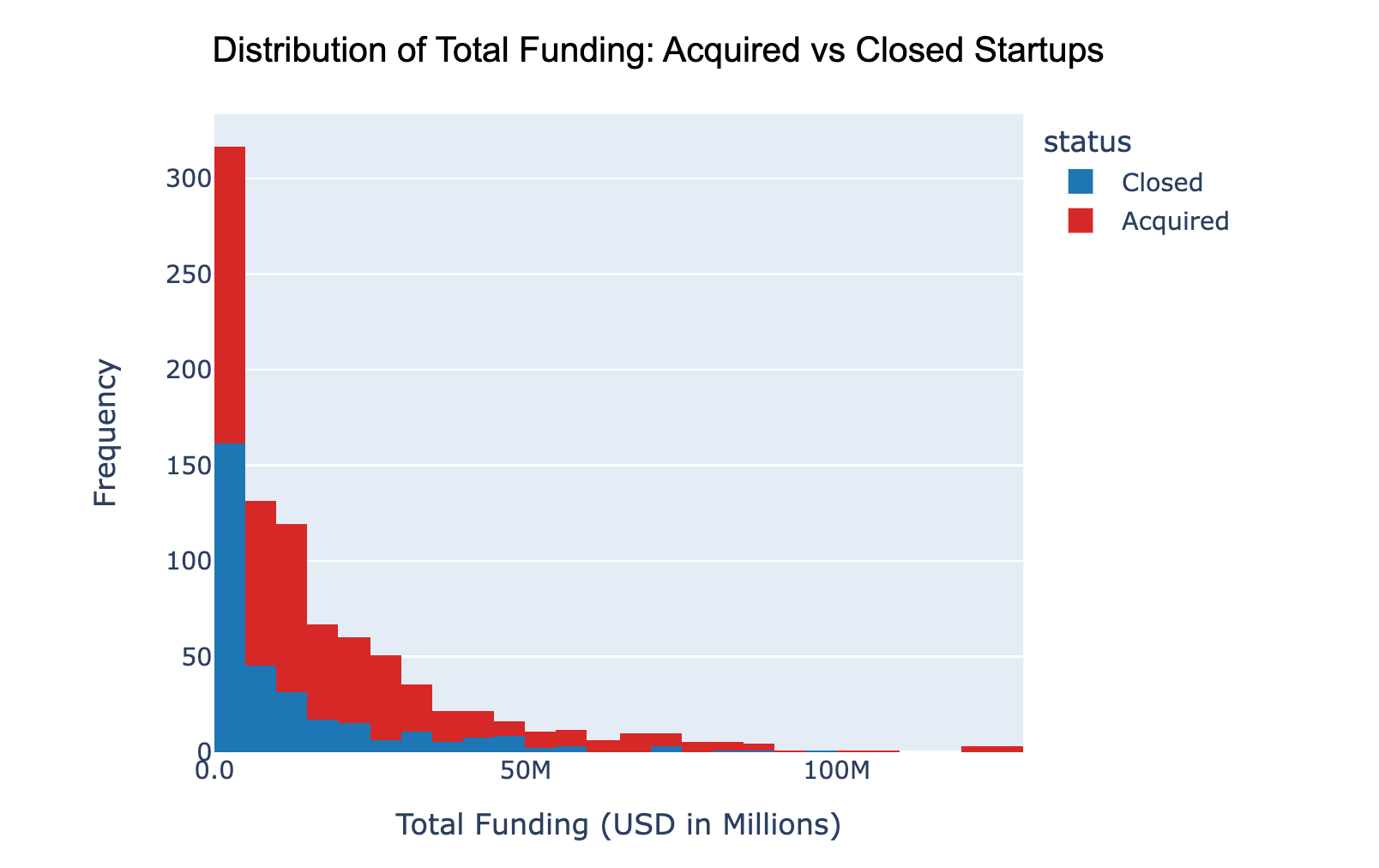

I’m a technical writer with a keen interest in Machine Learning. I write detailed, easy-to-understand articles to help you in your ML journey. I'm excited to share my discoveries and what inspires me in ML with you.