
I'm a Senior MLOps Engineer with 6+ years of experience building production-ML systems.
I write long-form articles on MLOps to help you build too!

Tackling Model Deployment can feel like deciphering a complex puzzle. 🧩 Say goodbye to confusion! This guide will simplify each piece, from understanding the key concepts to choosing the right tools for your use case as well as simplifying your path to ML success.
Choosing the right tools for deploying a machine learning model is an important decision, shaped by various elements. The specific use case and the needs of your team play a major role in this process. I’ve written this article to:
- Explain what Model Deployment and Model Serving are and outline the steps for deploying a model in a production environment.
- Provide essential tips for assessing your project’s requirements.
- Examine the advantages and disadvantages of the top machine learning deployment tools.
- Offer guidance on selecting a tool that aligns with your team’s needs and skills.
Let’s start by understanding the concept of Model Deployment, its role, and how it enables machine learning models to make a real-world impact. 👇
Understanding Model Deployment
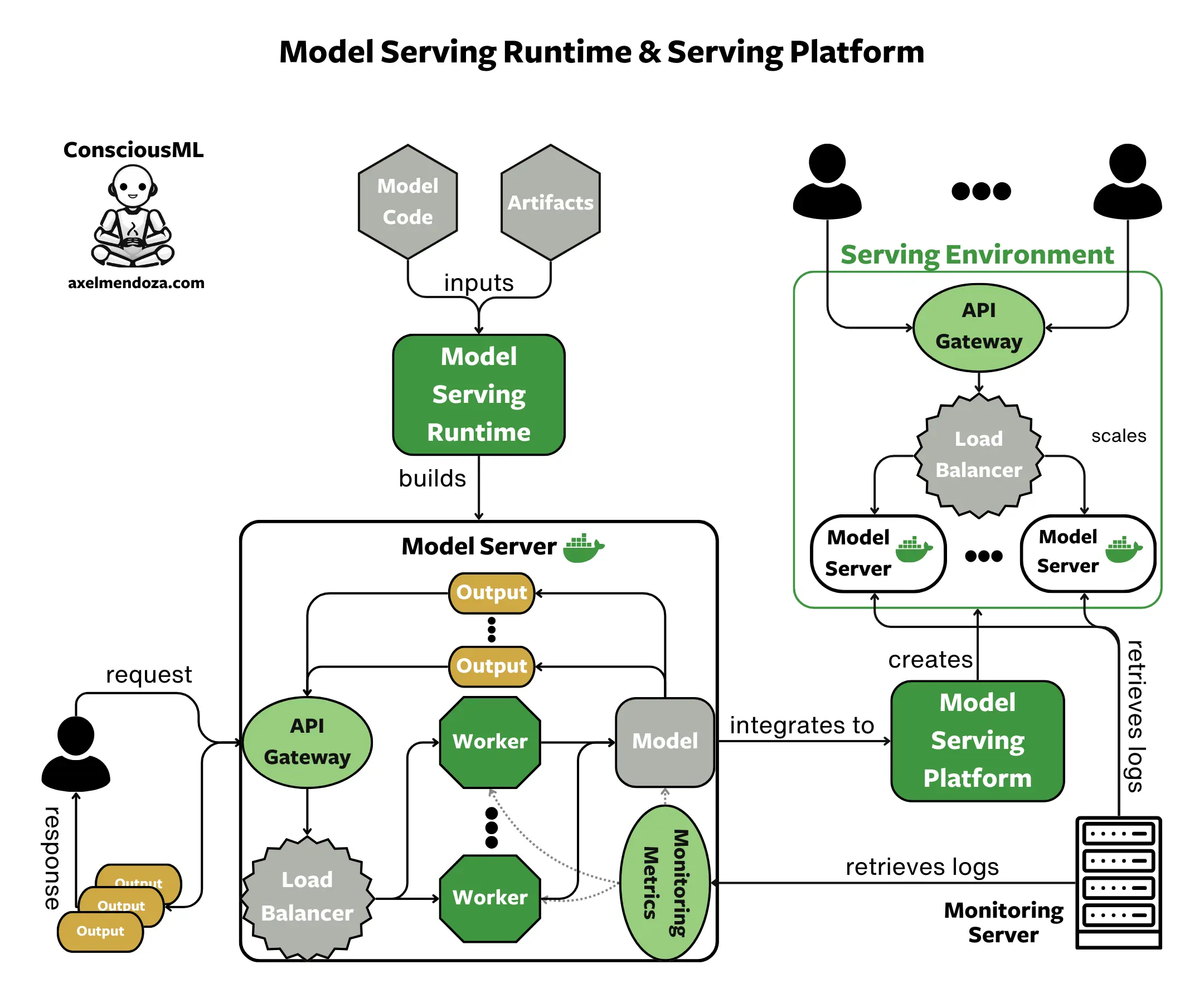
In this section, we will focus on Model Deployment, a crucial step in transforming theoretical ML models into practical applications.
Serving vs Deployment
In my experience as an MLOps engineer, I’ve noticed a common mix-up in the machine learning field: the terms Model Serving and Model Deployment often lack clear definitions. It seems like everyone has a unique understanding of what these terms mean.
So here’s my definition! Model Serving refers to making a machine learning model accessible via APIs. These APIs enable users to input data and get predictions 🔮 in return. In this step, we often use Docker to containerize the model for this purpose, enhancing its usability and portability.
In simple terms, Model Deployment refers to moving a machine learning model into a real-world setting. 🏭 This step ensures that the model is in a format that can be used effectively and connected to the necessary infrastructure, including servers and databases.
I find this definition practical because tools like TensorFlow Serving, BentoML, and TorchServe, which you often come across in the context of model serving, are primarily focused on building ML REST API interfaces. However, they don’t offer much direction on the actual deployment platform for the containerized model.
This article will focus on the deployment process. If you need guidance on how to serve your model, you can refer to my previous article on BentoML.
The Importance of Effective Model Deployment
Model Deployment significantly impacts the success of machine learning projects. A survey found that only 0 to 20% of machine learning models are successfully deployed, with over 80% not reaching this stage. This low success rate is often due to leadership issues in ML projects and MLOps challenges.
In an ML team, model deployment bridges the connection between different roles. Data scientists develop and evaluate ML models, while ML or MLOps engineers work on deploying it and handling user requests. Smooth collaboration here is key for machine learning product success.
Here’s the bottom line: picking the right tools for deployment can ease this collaboration. It’s important to choose tools that suit the abilities of both data scientists and MLOps engineers, leading to better project outcomes.
Now that we understand the importance of model deployment, let’s clarify the steps involved.
Steps to Deploy a Model in Production
Deploying a machine learning model into production involves several key steps:
- Experimentation: The initial step is where a model is created, trained on datasets, and evaluated. This phase focuses on model accuracy and performance.
- Serving: After experimentation, the model is containerized. Model Serving frameworks like BentoML, as discussed in a previous article, are used for this purpose. Containerization helps in managing and deploying the model effectively.
- Deployment: The next step involves deploying the dockerized model using specific tools or platforms. This stage is about choosing the right deployment environment that matches the needs of the model and users.
- Monitoring: Once deployed, it’s crucial to monitor the model. Tools like Prometheus, Evidently, or Arize, are used for tracking online performance, data drift, and system resources. This monitoring ensures the model operates effectively in its intended environment.
- Iterative Improvement: Post-deployment, collecting online metrics is vital. These metrics help in continuously refining and improving the model, based on real-world usage and feedback.
Now that we know the crucial steps to deploy a model, let’s see how we can evaluate the requirements of a project to further choose the right tool for our needs.
Evaluating Your Project Requirements

Deployment Complexity
The complexity of deployment is a primary consideration. It’s essential to align the deployment strategy with the technical capabilities of your team. A more straightforward deployment process may be favored by teams with limited resources or expertise, while others with more advanced technical capabilities may opt for a more complex, feature-rich deployment setup.
Real-time vs Batch Processing
Understanding the processing requirements, whether real-time or batch, is fundamental. Real-time processing demands a robust, low-latency infrastructure, suitable for use cases like fraud detection or real-time analytics. On the other hand, batch processing, which processes data in groups, maybe more suited for less time-sensitive use cases like daily data analysis or reporting.
Traffic Volume and Resource Requirements
Evaluating the expected traffic volume and resource requirements is critical. High-traffic scenarios may necessitate a robust infrastructure with powerful computational resources like GPUs, especially for compute-intensive machine learning models. On the contrary, lower traffic scenarios or less complex models may find CPUs adequate, reducing the operational cost.
Scaling To Zero
Cost is a pivotal factor in choosing a deployment strategy. Scaling-to-zero, the ability to scale down to zero resources when not in use, can significantly reduce costs. It’s essential to consider the cost implications of different deployment options and choose one that aligns with your budget while meeting the performance and resource requirements of your use case.
Having evaluated the key requirements for your machine learning project, it’s now time to explore the tools that can meet these needs.
Top ML Model Deployment Tools

Vertex AI
Vertex AI, a product from Google Cloud Platform, offers a managed environment for deploying machine learning models.
This tool is particularly beneficial for small to medium-sized teams that lack extensive machine learning teams and need support in model deployment. It’s well-suited for teams looking to outsource infrastructure management and who have the budget to handle higher operational costs.
Advantages
- Centralization and Accessibility: Simplifies operational work by offering a centralized, accessible platform.
- Visibility and Transparency: Provides an environment ideal for AI beginners.
- Managed Infrastructure: Involves minimal setup and maintenance for deploying ML models.
- Auto-scaling Endpoints: Automatically adjust API endpoints to handle varying traffic loads.
- Reduced Team Size: Diminishes the need for a large team to maintain ML projects.
- Support: Offers extensive support from Google.
Drawbacks
- High Cost: Involves more expensive operational expenses than a self-managed infrastructure.
- Complex Pricing: The pricing is not very straight forward and it is difficult to fully evaluate costs.
- No Scaling to Zero: Cannot scale down resources to zero when idle. An issue was opened in 2021 and it is still not in the roadmap at the time of the writing.
- Operational Limitations: Imposes specific methods of operation, reducing flexibility.
- Vendor Lock-in: Creates dependence on Google Cloud Services.
Ideal For
- For Small to Medium Enterprises: Ideal for smaller companies lacking extensive ML teams and seeking deployment support.
- Outsourced Management: Fits teams that prefer delegating environment maintenance to third-party services.
- Budget for High Costs: Works well for teams capable of managing higher cloud-related expenses.
Not Ideal For
- Not for Aligned Systems: Less suited for those with pre-existing systems incompatible with Vertex AI.
- Not for Flexibility: Not ideal for teams looking for decentralized, flexible ML operational platforms.
AWS Sagemaker
AWS SageMaker is a cloud-based machine learning platform, similar to Google’s Vertex AI, provided by Amazon Web Services.
Advantages
- Similar Benefits to Vertex AI: Shares many features with Vertex AI.
- Scaling to Zero: Offers the capability to scale-to-zero when not in use. Vertex AI does not offer this feature.
- Pricing: A more straightforward pricing structure than Vertex AI.
Drawbacks
- Similar as Vertex AI: Shares similar limitations as Vertex AI.
- Less User-Friendly: Vertex AI feels easier to use compared to Sagemaker.
As you might have understood, the target audience is pretty much the same as Google’s managed platform.
If you start from scratch and do not have a preference for AWS or GCP, I would go for Sagemaker as scaling to zero can save tremendous costs if your applications have down times.
Otherwise, I would advise choosing one or the other if your cloud infrastructure is already supported by these vendors. In my opinion, it is not worth investing the effort to use Sagemaker if you are on GCP and vice-versa.
Seldon Core
Seldon Core is an open-source tool orchestrating AI model deployment on Kubernetes, offering strategy-driven deployment like A/B testing, alongside real-time monitoring tools, encapsulating a straightforward path from model packaging to production.
Advantages
- Online Prediction Support: Strong capabilities for online prediction, especially with Kafka integration.
- Improved Documentation: Notable enhancement in documentation over recent years.
- Batch Prediction: Clear framework for batch prediction.
- Advanced Deployment Strategies: Facilitates Multi-Armed-Bandit and Canary deployments, along with A/B testing.
Drawbacks
- Kubernetes Dependency: Requires building and managing a Kubernetes cluster for full functionality.
- Framework Limitations: Limited support for some ML frameworks, like Pytorch needing Triton Server.
- Complex Inference Graphs: Supports complex graphs but requires significant engineering effort.
- Auto-scaling Challenges: Auto-scaling integration needs additional setup, such as KEDA.
- Lack of Scaling to Zero: Does not support reducing resources to zero when idle.
- Community Support: Only average community support is available.
- Monitoring Tools: Lacks comprehensive built-in model monitoring.
Ideal For
- Teams with a high MLOps expertise.
- Teams needing advanced deployment features.
- Companies requiring strong batch prediction features.
Not Ideal For
- Team running models on PyTorch as it required additional engineering.
- Companies with limited MLOps capabilities as it will eventually be required to build and manage a Kubernetes cluster.
KServe
KServe is an open-source tool providing a Kubernetes-native platform for scalable machine learning models, simplifying the deployment process, and ensuring a direct, manageable transition from model to operational service.
KServe and Seldon Core are competitors in the MLOps field. When choosing between them, a detailed evaluation of your existing stack is crucial. Both platforms offer notable benefits and have their own limitations. This careful analysis is key to finding the tool that best fits your project’s requirements and existing infrastructure.
Advantages
- Online Prediction: Strong support for online prediction.
- Documentation: Well-documented with consistent contributions.
- Auto-scaling: Best in-class auto-scaling capabilities.
- ML Framework Support: Compatible with various ML frameworks including TensorFlow, PyTorch, and more.
- Complex Inference Graphs: Efficient handling of intricate inference graphs.
- gRPC Protocol: Excellent support.
- Community Support: Active and helpful community.
- MLOps Integration: Wide range of integration with other MLOps tools.
- Deployment Strategies: Supports Multi-Armed Bandits, A/B testing, and Canary deployments with additional engineering.
Drawbacks
- Batch Prediction: Challenges in providing an efficient batch prediction solution.
- Kubernetes Management: Requires building and managing a Kubernetes cluster, complex for teams without dedicated DevOps.
- Lack of Built-in Monitoring: No out-of-the-box solution for model monitoring.
Ideal For
- Teams needing advanced deployment features and integration with various MLOps tools.
- Companies with strong DevOps or MLOps capabilities.
- Budget-conscious teams benefiting from scale-to-zero capabilities.
Not Ideal For
- Companies with limited MLOps capabilities.
- Projects with a high volume of batch predictions.
After going through the key features of the top four model deployment tools, I’m ready to share some extra tips. In the next section, we’ll dive into these additional insights to further guide your deployment strategy.
Selecting the Ideal Model Deployment Tool

This section focuses on helping you decide whether to use Kubernetes-based or fully managed tools for ML model deployment. It will cover key aspects like features, team size, budget, and project needs, aiding in an informed choice.
Kubernetes Considerations
First of all, we will make a brief analysis of Kubernetes as it has become a staple in the model deployment field.
State of the Art in ML Deployment
Kubernetes excels in orchestrating containerized applications, making it a robust solution for deploying machine learning models. Its capabilities in automating deployment, scaling, and managing containerized applications are unparalleled. Additionally, its extensive community support and well-documented resources make it a go-to choice for many organizations.
Learning Curve
Kubernetes, while powerful, has a steep learning curve that can be a barrier for many teams. Mastering its complexities requires a significant investment in engineering and cloud resources. This learning curve can slow down the deployment process, especially for teams new to container orchestration.
Heavy Maintenance
Kubernetes demands a notable amount of resources not only to set up but also to develop and support the infrastructure over time. The ongoing requirement of time and expertise to ensure the infrastructure remains robust and updated can be intensive. This aspect can pose a challenge for teams with limited resources or those looking to minimize operational overheads.
After reviewing the strengths and weaknesses of this tool, deciding on your deployment stack really comes down to the following question: open-source or fully managed?
Fully-Managed Tools
Fully-managed tools, such as Vertex AI or AWS Sagemaker present a practical alternative for those looking to avoid the complexity of Kubernetes. As highlighted in the previous section, these tools are designed for ease and efficiency, making them a favorable choice for certain project environments.
The main advantages are:
- Simplicity and Ease of use: Ideal for teams seeking straightforward and rapid deployment.
- Fast Adoption: Reduces technical debts dramatically thanks to straightforward development and extensive vendor support.
- Reduces Infrastructure Management: Reducing the need for substantial infrastructure is key for iterating quickly on ML product developments.
You might wonder why is it worth considering open-source tools when fully-managed ones have clear benefits. The short answer is cloud costs and customization.
Open-Source Tools
The main benefits of open-source tools such as KServe or Seldon are:
- Customization: High customization capabilities for advanced deployment strategies.
- Lower Cloud Costs: Infrastructure costs will be dramatically reduced compared to third-party services. However, bear in mind that during development, the salary cost of the employees will, in most cases, largely outweigh the cost of a fully managed tool.
- Integration: Easier integration with various MLOps tools.
Here are the reasons why I would choose a Kubernetes-based open-source tool over a fully managed one:
- The company requires a high degree of flexibility and customization in terms of MLOps features.
- If we know in advance that the data volume and model inference traffic will be high, it is worth spending extra engineering budget to save long-term cloud costs.
- If your team has an already established stack, going for an open-source tool can be a wiser choice due to the higher integration capability.
- Your team has the expertise to manage a Kubernetes cluster.
Conclusion
As we wrap up, revisiting the pivotal considerations in choosing a deployment strategy is essential: the technical capabilities of your team, the specific needs of your use case, and the cost implications are at the forefront. 💰
It’s crucial not to only consider your current needs but also to anticipate future requirements, including expected traffic and potential scaling necessities. 📈
I encourage a deeper exploration of the discussed deployment options, understanding their pros and cons to better align with your objectives.
A warm thank you for your time and engagement. 💖 I hope this article can provide some help in your deployment decisions. Good luck on your ML journey!